Le KZS Lab, une cinquantaine de projets par an, presque autant de clients différents, chacun avec ses contraintes. On retrouve néanmoins deux grandes typologies de projets : soit le client fourni tout (dépôts GIT, infra, matériel, etc) soit il ne fournit rien et dans ce cas Kaizen Solutions est relativement libre de ce qu’il peut utiliser. Dans ce cas précis, on se retrouvait assez couramment avec le code sur Gitlab.com, un peu de Docker pour l’artefact final et rarement du déploiement, principalement par contrainte technique (pas d’infra à disposition, pas aisé de sécuriser l’accès et/ou les communications, ...). De plus, très peu de projets utilisaient la Gitlab CI : nombre de minutes limitées (ok, ce n'est pas vraiment une excuse 😊), mais souvent manque d’expérience, de savoir-faire ou encore de sensibilisation. Plusieurs explications à cela :
- Collaborateurs juniors pas encore sensibilisés / à l’aise avec ces pratiques
- Pratiques encore peu répandues dans certains secteurs (informatique embarquée, DataScience, IA, ...)
- Peu d’exemples sur étagère, manque de templates de projets pour simplifier la vie des développeurs
Dans l’ensemble, cela tournait quand même assez bien, et les quelques sachants tentaient de faire avancer les choses. Mais un jour, un client est venu avec un projet où :
- Il n’était pas capable de nous fournir un dépôt Git, l’infra, ...
- Et avait la contrainte d’être sûr de l’infrastructure "souveraine" : comprendre ici Française, ou au pire Européenne (aussi bien dans la localisation que dans la législation)
Patatras ! Sacrebleu ! On n’a pas ça nous ! Le projet est en plus super intéressant, et on n’a pas envie que cet élément fasse capoter le partenariat ! Du coup, on part en quête de solutions...
Les choix des briques de base
- Notre DSI : un Gitlab existe, mais il est sur une infrastructure Azure, donc pas acceptable. Poser un nouveau Gitlab "on premise" n’est pas possible : un gros chantier infra est en cours et plein d’éléments divers font que la demande ne pourra aboutir avant plusieurs mois.
- Utiliser un service externe sur étagère : nos recherches ne nous ont pas montré beaucoup de fournisseurs et une offre en infogérance avait un coût prohibitif pour notre besoin.
- Dernière solution, OVH : on était quand même un peu frileux, l’incendie de Strasbourg s’était produit quelques jours avant...
On se met malgré tout à éplucher leur catalogue, voir quel service nous limite le risque si un autre désastre venait à se produire et toutes les parades que l’on peut mettre en place. Cet incendie a au moins eu la vertu de bien mettre en avant les questions de sauvegarde et de DRP (Disaster Recovery Plan).
Notre choix se porte donc :
- Sur un Gitlab EE (sans licence payante) en mode Cloud Native Helm,
- Un petit cluster Kubernetes de 2 machines chez OVH (Kubernetes managé),
- L’utilisation des ObjectStorage (équivalent des buckets S3) de chez OVH afin de limiter la maintenance et les risques de perte.
On choisit aussi tout ce qui va bien :
- Monitoring d’infrastructure K8S classique via Prometheus
- Surveillance externe via New Relic
- Cert-manager pour la gestion de l’ensemble des certificats (challenge HTTP-01 et DNS-01 pour les "pages")
- De la sécu via le cloisonnement des namespaces, Kaniko, ...
Les avantages de ces choix :
- Monitoring interne facile pour brancher des outils rapidement tels que Lens
- Monitoring externe, non tributaire d’OVH pour alerter en cas de soucis
- Sauvegarde sur un Bucket dédié présent dans un autre Datacenter OVH
- GitlabEE : si demain on souhaite payer une licence on n’aura pas grand-chose à changer
- Cert-manager : la magie des certificats automatiques
- Kubernetes : scaling des services présents dans l’infra, résilience et scaling de l’infrastructure elle-même (et toutes les autres bonnes raisons de choisir K8S 😊 )
- Les object storage limitent fortement les dégâts en cas d’incident chez OVH
- HELM : choix de faire une chart par-dessus la chart Gitlab : permet de simplifier grandement la gestion des valeurs et secret
- Automatisation complète de l’installation via HELM (monitoring, cert-manager, Gitlab, ...)
La mise en place
Maintenant que les choix techniques ont été faits, nous savons avec « quoi », et grossièrement « comment » nous souhaitons poser notre forge.
Un point important à garder en tête : nous souhaitons que tout soit le plus automatisé/scripté possible pour plusieurs raisons :
- Limiter les erreurs humaines
- Permettre une reproductibilité
- Faciliter les installations / mises à jour
- Et pourquoi pas, avoir la capacité de déployer cela autre part (autre infra, chez un client, ...)
Un seul élément n’est aujourd’hui pas scripté, la création de l’infrastructure Kubernetes chez OVH, principalement faute de temps et de ROI suffisant. Si et quand nous le ferons, le choix se portera tout naturellement sur Terraform. Pour le reste, tout est dans Kubernetes, sur les bons conseils de quelques collègues. Nous avons créé des chart Helm par-dessus les charts officiels, cela donne plusieurs avantages :
- Figer les versions des charts utilisées : permet de gagner en reproductibilité et maitriser les moments où l’on monte les versions.
- Permet de stocker les surcharges de valeur Helm dans des fichiers dédiés et donc de faciliter le versionning.
- Permet ensuite de rajouter nos propres éléments dans la chart (pod spécifique, config/secret, ...).
Nous avons principalement 3 charts qui gèrent la partie Gitlab/Forge :
- Ingress (ici NginX), avec quelques configurations spécifiques à OVH et Gitlab,
- Cert-manager, avec les challenge HTTP et DNS,
- Et bien sur Gitlab.
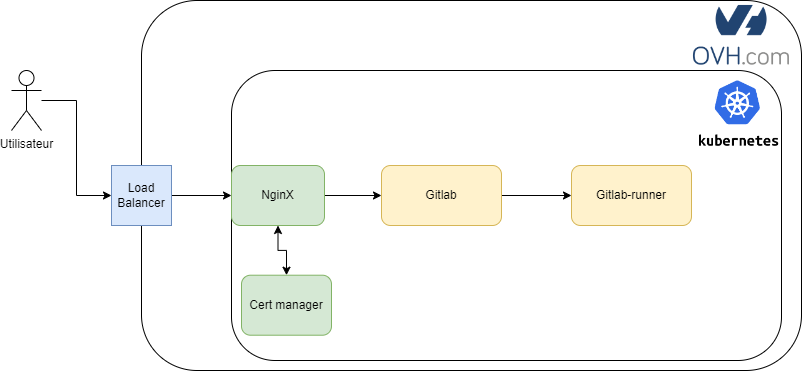 Diagramme Nginx Gitlab cert manager
Diagramme Nginx Gitlab cert manager
Prenons l’exemple de notre chart Ingress, nous l’avons créée avec la commande helm create ingress-forge, puis avons supprimé l’ensemble du contenu du dossier templates (dans notre cas cela ne nous sert pas). Les deux éléments importants sont :
- La déclaration de dépendances dans le Chart.yaml
dependencies:
- name: ingress-nginx
version: "3.39.0"
repository: "https://kubernetes.github.io/ingress-nginx"
- Le fichier de values.yaml
ingress-nginx:
tcp:
22: "gitlab/gitlab-gitlab-shell:22:PROXY"
controller:
service:
type: ClusterIP
Ici, on peut voir le type « ClusterIP » et pas « LoadBalancer » : c’est volontaire, nous avons dans la même chart une définition du load balancer avec quelques configurations en plus et qui dans la majorité des cas pointe vers ce ClusterIP. Cette pirouette est là pour :
- Garantir qu’on ne supprime pas le LoadBalancer par inadvertance ou par modification de la Chart Gitlab, ce qui aurait pour conséquence de changer son IP lors de sa recréation ;
- Rajouter les forwarding pour les ports non HTTP (GIT+SSH entre autres) ;
- Permettre l’utilisation des en-têtes de proxy afin de garder les IP sources.
Le cert-manager suit exactement la même logique :
dependencies:
- name: cert-manager
version: "1.5.4"
repository: "https://charts.jetstack.io"
cert-manager:
installCRDs: true
ingressShim:
defaultIssuerName: letsencrypt-prod
defaultIssuerKind: ClusterIssuer
extraArgs:
- --dns01-recursive-nameservers-only
- --dns01-recursive-nameservers=8.8.8.8:53,1.1.1.1:53
cert-manager-webhook-ovh:
groupName: pages.forge.kaizen-solutions.net
Ici, néanmoins, quelques subtilités supplémentaires, dans deux dossiers :
- templates
- ovh-secret.yaml qui contient le secret pour accéder à l’API OVH pour le challenge DNS-01
- production-issuer.yaml l’issuer pour les certificats classiques en challenge HTTP
- production-issuer-dns.yaml l’issuer pour les certificats en challenge DNS (ici pour les pages)
- rbac.yaml Le RBAC du service account cert-manager
- staging-issuer.yaml L’issuer de test
- charts
Quelques informations générales :
- Les issuers sont définis en tant que ClusterIssuer, ce qui permet d’en avoir un seul pour gouverner tout le cluster.
- Le challenge DNS-01 est nécessaire pour activer la feature « pages » de Gitlab, car elle nécessite un certificat wildcard.
Enfin la dernière partie, et certainement la plus complexe : Gitlab ! Ici, nous avons fait les choix suivants, l’objectif étant d’éviter autant que possible le recours à des volumes persistants si une solution « as-a-service » est possible :
- Postgres dans le cluster, au moment de la mise en place OVH ne proposait pas de "Postgres as-a-service"
- Utilisation des ObjectStorage d’OVH et pas de Minio (préférence pour un service managé)
- Désactivation du Prometheus et du Cert-manager embarqué par défaut dans la chart, car déjà déployé de manière globale au sein du cluster
- Réduction de certains réplicas, request et limit pour rentrer dans l’infra : rappelons que la chart est prévue pour des installations avec plus de 2000 utilisateurs, nous sommes 200
- Configuration de plusieurs OIDC : Azure pour nos collabs, KeyCloak pour les externes, Gitlab.com pour permettre le rapatriement des projets
- Rajout d’un service plantUml pour générer les graphs UML
Je ne rentrerai pas dans le détail de toutes les configurations, ce serait trop long, et la doc de la Chart Gitlab est assez complète, mais seulement des plus importantes à nos yeux :
- Limiter les request/limits des runners (éviter qu’ils n’explosent le cluster !) et activer le cache S3
gitlab-runner:
runners:
cache:
secretName: gitlab-cache
config: |
[[runners]]
[runners.kubernetes]
image = "ruby:2.5"
helper_image_flavor = "ubuntu"
helper_cpu_request = "50m"
helper_cpu_limit = "200m"
helper_memory_request = "256M"
helper_memory_limit = "800M"
cpu_request = "250m"
cpu_request_overwrite_max_allowed = "1500m"
cpu_limit = "1500m"
cpu_limit_overwrite_max_allowed = "4000m"
memory_request = "256M"
memory_limit = "2000M"
memory_request_overwrite_max_allowed = "4000M"
memory_limit_overwrite_max_allowed = "4000M"
[runners.cache]
Type = "s3"
Path = "runner"
Shared = true
[runners.cache.s3]
ServerAddress = "s3.gra.cloud.ovh.net"
BucketName = "gitlab-cache"
BucketLocation = "gra"
Insecure = false
Nous souhaitions que les backups se fassent sur un autre bucket (géographiquement séparé) que ceux de la forge (amer souvenir de l’incendie OVH)
task-runner:
persistence:
enabled: true
storageClass: csi-cinder-classic
extraVolumeMounts: |-
- name: gitlab-backup-s3
readOnly: true
mountPath: "/etc/s3-backup"
extraVolumes: |-
- name: gitlab-backup-s3
secret:
secretName: gitlab-backup-dest-storage
backups:
cron:
enabled: true
extraArgs: --s3config /etc/s3-backup/.s3cfg
schedule: '@daily'
persistence:
enabled: true
storageClass: csi-cinder-classic
size: 120Gi
objectStorage:
config:
secret: gitlab-backup-source-storage
key: config
Nous avons maintenant une forge opérationnelle, des vrais runners en illimité (et lancés au sein de la même infrastructure), du SSO pour simplifier le processus d’authentification…
La prochaine partie portera sur les premières subtilités dans l’utilisation de la forge (spoiler alert : docker build ne marche pas), mais aussi les succès : CI/CD à foison, déploiement d’environnements, etc.
L’usage, les subtilités, et le maintien en vie de la forge
L’ouverture de la forge s’est passée en deux temps : une première étape avec quelques projets sur lesquels les équipes étaient motivées et compétentes pour tester et debugger les premiers problèmes, puis une seconde où l’on a rapatrié tous les projets depuis Gitlab.com.
Le build
Durant cette première phase, nous avons pu tester avec succès le déploiement des pages (et le certificats wildcard de let’s encrypt), les build gitlab CI : pour rappel nous utilisons les runners au sein de Kubernetes. Ces runners sont donc des containers Docker. Le premier point (mais vous l’aviez peut-être remarqué dans la configuration des runners du précédent article) est l’image de base si l’utilisateur ne la spécifie pas.
En effet, sur Gitlab.com, cette image de base est « ruby:2.5 », alors que dans la configuration par défaut des runners de la chart Helm c’en est une autre. Nous avons pris la décision de tenter de nous rapprocher autant que possible de la configuration Gitlab.com et avons donc changé cette image par défaut pour « ruby:2.5 »
Ensuite, un autre point complexe et dont la solution actuelle ne nous convient pas totalement : le build d’image Docker. L’utilisation de la commande Docker au sein d’un container possède plusieurs contraintes : montage du socket du démon Docker, ainsi que faire tourner le container en mode « privileged ». Ceci ne nous convenait pas du tout, principalement pour toutes les problématiques de sécurité que cela peut poser : un container avec des accès privilégiés peut faire n’importe quoi au niveau de la machine hôte, et donc une personne mal intentionnée pourrait détruire un nœud du cluster Kubernetes ou encore accéder aux autres containers.
Deux solutions alternatives sont possibles : création d’instance de runner dédié, hors du cluster Kubernetes et avec une durée de vie très courte (potentiellement un seul job), mais nous ne sommes pas encore assez matures pour cela. L’autre solution consiste à l’utilisation de Kaniko, produit de Google permettant de construire des images Docker sans besoin d’un démon Docker. Cette solution fonctionne bien et s’intègre aisément dans un build CI. Mais possède tout de même certaines lacunes qui font que nous ne sommes pas totalement satisfaits :
- Le build est globalement plus long, et dans certains cas extrêmement longs (build Angular avec tous les petits fichiers issus d’un node_modules par exemple).
- L’usage mémoire du build est très élevé et dans certains cas (toujours Angular par exemple), la consommation mémoire peut facilement atteindre plusieurs gigas.
Cette solution étant tout de même fonctionnelle, elle nous permet de patienter en attendant de trouver mieux. Nous explorons actuellement des solutions avec Podman, mais nous ne les jugeons pas encore suffisamment transparentes en termes d’impact sur le cluster Kubernetes pour être mises en place.
Le déploiement projets
Enfin, la partie déploiement : une volonté autour de cet écosystème est aussi de permettre de déployer facilement des environnements de test afin de pouvoir montrer et partager nos prototypes directement avec le client.
Pour y parvenir tout en conservant un niveau de sécurité correspondant à nos exigences, nous sommes partis sur le respect de plusieurs bonnes pratiques :
- Un namespace par binôme projet-environnement (par exemple projet1-staging, projet1-test, projet2-test, ...)
- Un service account (hormis les admin et système) ne peut avoir accès à deux namespaces
- Une isolation totale des namespaces entre eux (communication inter namespace impossible)
- Un seul Ingress controller et certCmanager pour l’intégralité du cluster
- Des limites de ressource fortes sur les namespaces (ResourceQuota) et donc la mise en place de « default limit/request » pour l’ensemble des pods (LimitRange)
- Des accès restreints aux types d’API fourni par Kubernetes
- L’interdiction de monter des PVC et des LoadBalancer
Certaines de ces contraintes peuvent être fortes et sont bien entendu désactivables avec le bon argumentaire au cas par cas. Cela permet aussi d’accompagner les projets dans une philosophie container : a-t-on vraiment besoin de stockage à tel endroit ? A-t-on réellement besoin de CPU/RAM pour un NginX ? Comment optimiser la répartition des ressources allouées… ?
La création du namespace, des règles de sécurité, des service account et de tout le nécessaire à un projet est bien entendu scripté afin de faciliter la création mais aussi permettre de les maintenir dans le temps.
La montée en charge
Nous avons maintenant un écosystème prêt (et surtout documenté !) pour permettre à tout le monde de se connecter, de travailler, de builder et de déployer nos différents projets. Il est donc enfin venu le temps de réaliser la montée en charge : rapatrier les projets Gitlab.com et faire de cette forge la « norme » pour nos projets.
Gitlab propose d’importer automatiquement des projets depuis Gitlab.com, mais (il y a toujours un mais !) cette solution fait l’impasse sur certaines features tels que le Wiki.
Nous avons donc écrit un petit script pour référencer les 200 projets sur Gitlab.com et vérifier lesquels utilisaient ces features : ouf il n’y en avait que quelques-uns. Nous avons donc utilisé l’import automatique pour tous les autres projets, puis sommes passés par un cycle d’export/import classique pour les quelques autres, afin d’éviter toute perte de données/informations.
Certains jobs CI ont dû être adaptés pour remplacer Docker build par Kaniko, faire évoluer les URLs des registry Docker (ou autre Package registry), mais au global, cela a été très fluide et permet un usage beaucoup plus intensif de l’intégration continue, mais aussi du déploiement d’environnement (notamment de tests) de manière automatique et aisément exposable au client.
Conclusion
Au fil de ces trois parties, nous avons vu le cheminement de la création de cette forge en adéquation avec nos objectifs et contraintes.
Retour aux articles