TL;DR : Comment 3 développeurs ont refactorisé 18 API et 5 workers en .NET en faisant de l'OpenAPI la source unique de vérité. Gain : validation commune, messages d'erreur normalisés (RFC 7807), fin des divergences entre micro-services. Coût : 1,5 semaine de dev pour la lib commune, 3 mois pour propager la release.
Le problème : 18 micro-services, 5 ans de dette, 0 contrat commun
D'après le Postman State of the API Report 2025, 82 % des organisations se déclarent désormais "API-first" ou en transition, contre 74 % en 2024. Notre projet illustre ce mouvement à l'échelle d'un parc industriel mature.
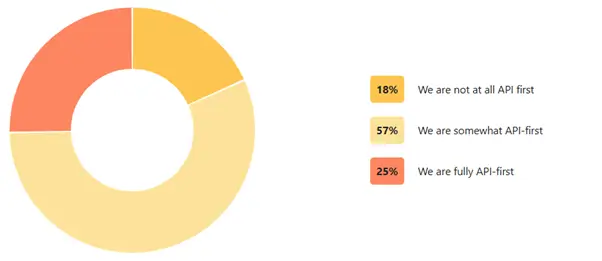
Source : https://www.postman.com/state-of-api/2025/#introduction
Sur la plateforme IoT d'un acteur industriel mondial (capteurs connectés, edge devices, plateforme cloud), notre équipe maintient :
- 18 API REST exposées aux clients B2B
- 5 workers (consommateurs de Service Bus)
- 4 environnements (dev, QA, pré-prod, prod) sur Azure Kubernetes
- ~60 repos au total, pour 3 développeurs et 1 DevOps
Le projet a été entièrement migré d'un monolithe à des micro-services par découpages successifs, sans brique commune définie en amont.
Les symptômes
Trois irritants se sont accumulés :
- Réponses d'erreur incohérentes entre services. Pour le même cas métier (device inaccessible, droits insuffisants), un service renvoyait 401 Unauthorized, un autre 404 Not Found, un troisième un code custom. Le client final ne savait pas diagnostiquer.
- Documentation et code désynchronisés. L'OpenAPI exposée aux utilisateurs était maintenue à la main, à côté du code. Une modification du code n'entraînait pas mécaniquement la mise à jour de la spec d'où des « bugs » qui n'étaient que des écarts documentaires.
- Validation dupliquée à 18 endroits. Chaque service réimplémentait ses propres règles de validation (regex Device ID, format d'URL, contraintes de version), avec des dérives subtiles d'un service à l'autre.Idem pour les tests, comme ils étaient dupliqués, certains tests n'étaient pas faits alors que c’était le le même cas.
Ces irritants ne sont pas spécifiques à notre projet. L'étude Gatepoint Research « Trends in API Program Improvements » (2025), commanditée par SmartBear auprès de 53 dirigeants de l'ingénierie, confirme la nature systémique du problème :
- 23 % citent l'incohérence des standards de design et de documentation comme leur principal défi ;
- 62 % déclarent vouloir accélérer la livraison de leurs API, mais 49 % opèrent encore à un niveau de maturité ad hoc ou émergent ;
- 64 % identifient la hausse des coûts opérationnels comme le principal risque à ne pas moderniser ;
- 51 % automatisent désormais les tests de contrat — un signal fort en faveur des approches doc-first.
Autrement dit : la fragmentation des standards est un goulot d'étranglement reconnu à grande échelle, et l'industrie bascule progressivement vers la validation automatisée par contrat.
Au passage à la nouvelle plateforme cloud conforme aux normes cybersécurité du groupe, il a fallu refactoriser massivement. Nous en avons profité pour traiter la racine du problème.
La réponse : approche doc-first OpenAPI
Définition
L'approche doc-first (aussi appelée contract-first ou API-first) consiste à écrire la spécification OpenAPI (standard maintenu par l'OpenAPI Initiative sous l'égide de la Linux Foundation) avant le code, puis à faire de ce fichier la source unique de vérité pour :
- la validation des requêtes entrantes,
- les schémas de réponse (succès et erreur),
- la documentation exposée aux consommateurs de l'API,
- les tests d'intégration.
Le code applicatif se branche sur la spec ; il ne la précède plus.
Le principe appliqué

Côté serveur, un middleware unique lit l'OpenAPI au démarrage, charge les schémas en mémoire, et intercepte chaque requête HTTP avant qu'elle n'atteigne le contrôleur. Si la requête ne respecte pas le contrat (regex non matchée, énumération invalide, champ obligatoire absent), elle est rejetée avec une réponse normalisée.
 Flux d'une requête HTTP avec validation OpenAPI. La requête est interceptée avant le contrôleur ; en cas d'échec, le client reçoit une erreur normalisée au format Problem Details (RFC 7807).
Flux d'une requête HTTP avec validation OpenAPI. La requête est interceptée avant le contrôleur ; en cas d'échec, le client reçoit une erreur normalisée au format Problem Details (RFC 7807).
Architecture technique : ce qui a réellement changé dans le code
 Avant : 18 services × 4 préoccupations transverses (validation, erreurs, logs, copie de la spec). Après : 1 spec OpenAPI + 3 NuGet communs consommés par les 18 services.
Avant : 18 services × 4 préoccupations transverses (validation, erreurs, logs, copie de la spec). Après : 1 spec OpenAPI + 3 NuGet communs consommés par les 18 services. Avant
Chaque service contenait :
- son propre code de validation (regex, longueurs, formats) ;
- son propre formatage d'erreur (souvent un objet maison, parfois ProblemDetails, parfois du texte brut) ;
- un fichier de logs avec des IDs référencés à la main ;
- une copie partielle de l'OpenAPI, à maintenir manuellement.
Après
Trois briques communes packagées en NuGet :
| Brique | Rôle |
| Lib de validation OpenAPI | Middleware ASP.NET Core qui lit la spec au démarrage et valide chaque requête |
| Lib de mapping d'erreurs | Mappe les exceptions C# vers le format Problem Details (RFC 7807) |
| Lib de logs communs | Logs structurés réutilisables (avec surcharge possible par service) |
Côté service consommateur, l'intégration tient en deux lignes dans Program.cs :
builder.Services.AddOpenApiValidation(options =>
{
options.SpecificationPath = "openapi/spec.yaml";
});[
Le contrôleur ne contient plus aucune validation manuelle sur les formats d'entrée. Il garde uniquement la validation fonctionnelle (« le device existe-t-il en base ? », « l'utilisateur a-t-il les droits ? »).
Gestion des erreurs custom
Pour les cas spécifiques à un service, un attribut décoratif fait le pont :
[WebApiExceptionMapping(
Title = "Device revoked",
StatusCode = 409,
Type = "https://example.com/errors/device-revoked"
)]
public class DeviceRevokedException : Exception { ... }[
Lever l'exception suffit : le middleware se charge du formatage en Problem Details et du log associé.
Bénéfices mesurés
| critère | avant | après |
| Implémentations de validation | 18 (une par service) | 1 (lib commune) |
| Formats de réponse d'erreur | Hétérogènes | Problem Details (RFC 7807) uniforme |
| Délai de propagation d'un changement de spec | N services à modifier à la main | 1 PR sur la spec + bump NuGet |
| Risque de divergence doc/code | Élevé | Quasi nul (la spec est le code) |
| Tests | Spécifiques à chaque service, partiellement basés sur la spec | Tests d'intégration à tous les niveaux lisant directement l'OpenAPI |
Effort total :
- Lib commune : 1,5 semaine pour un développeur.
- Refacto des 18 services + mise à jour des domaines : 5 développeurs sur ~3 mois (incluant le process de release groupe).
Pourquoi nous n'avons pas généré le code depuis l'OpenAPI
C'est une question récurrente : pourquoi ne pas utiliser un générateur (NSwag, OpenAPI Generator) pour produire automatiquement les contrôleurs depuis la spec ?
Quatre raisons concrètes :
- Base de code existante. 18 API matures, avec des DTO, des mappings, des décorateurs métier. Régénérer aurait été équivalent à réécrire.
- Couplage fort avec la lib générée. Un générateur impose ses templates ; toute personnalisation devient un combat.
- Versions OpenAPI supportées. Les générateurs accusent souvent du retard sur les versions récentes du standard OpenAPI.
- Adoption d'équipe. L'écosystème .NET privilégie le runtime, et nos développeurs n'étaient pas prêts pour un workflow de génération en pré-compilation.
Le choix de la validation runtime plutôt que de la génération compile-time est donc pragmatique : il préserve l'existant tout en garantissant l'alignement spec/code.
Tests : la spec comme oracle
Les tests d'intégration (niveau service avec mock et niveau déploiement en mode boite noire) chargent directement l'OpenAPI et dérivent leurs assertions :
[Fact]
public async Task RequestLogs_InvalidDeviceId_Returns400()
{
var response = await _client.GetAsync($"/devices/{INVALID_ID}/logs");
response.StatusCode.Should().Be(HttpStatusCode.BadRequest);
var problem = await response.Content.ReadFromJsonAsync<ProblemDetails>();
// Le schéma attendu vient directement de l'OpenAPI
problem.Should().MatchSchema(OpenApiSpec.GetErrorSchema(
path: "/devices/{deviceId}/logs",
verb: "GET",
status: 400
));
}[
Les testeurs métier se basent sur le même fichier. Conséquence : si nos tests passent, les leurs aussi, parce que la spec est partagée.
Pièges et angles morts
Trois points à anticiper si vous lancez la même migration :
- Gérer le 500 global. Le middleware ASP.NET par défaut renvoie une trace texte brute si une exception non décorée remonte. Penser à un catch-all qui réémet en Problem Details, sinon les clients reçoivent un body inutilisable.
- Validation runtime, pas compile-time. Un dev peut écrire un contrôleur dont la signature ne matche pas la spec : il ne le verra qu'à l'exécution. À compenser par des tests d'intégration robustes.
- Migrer .NET 8 → 9 (et OpenAPI 3.0 → 3.1). Microsoft a fortement remanié les abstractions OpenAPI dans .NET 9. Prévoir une fenêtre de refacto dédiée chez nous.
Faut-il faire pareil ?
Cette approche apporte une vraie valeur dès lors que trois conditions sont réunies :
- Plusieurs API à maintenir (au-delà de 3–4 services, les bénéfices explosent).
- Plusieurs consommateurs (équipe front, partenaires, clients B2B) donc une exigence forte de cohérence des contrats.
- Une équipe prête à investir dans les briques communes (lib NuGet, CI, release coordonnée).
Pour un mono-API ou un produit MVP, l'overhead n'en vaut probablement pas la peine.
FAQ
Doc-first, contract-first, API-first : quelle différence ?
Les trois termes sont quasi-synonymes. Doc-first met l'accent sur la documentation comme livrable, contract-first sur le contrat d'interface, API-first sur la priorité organisationnelle. En pratique, tous désignent une démarche où la spec OpenAPI précède le code.
Pourquoi RFC 7807 Problem Details ?
C'est un standard IETF (2016) qui définit un format JSON normalisé pour les erreurs HTTP : type, title, status, detail, instance. Adopté par .NET, Spring, et la plupart des frameworks modernes. Il évite à chaque équipe de réinventer son format d'erreur.
Quel impact sur les performances ?
Le middleware charge la spec une seule fois au démarrage et travaille sur des objets en mémoire. Surcoût négligeable par requête (validation regex + lookup de schéma).
Comment versionner l'OpenAPI ?
Dans notre cas, le fichier OpenAPI vit dans un repo dédié, versionné en sémantique. Les services consommateurs référencent une version précise via NuGet. Une PR sur la spec déclenche les tests de tous les services concernés.
Et pour les workers (consommateurs Service Bus) ?
Les workers n'exposent pas d'API HTTP mais utilisent les mêmes libs communes pour les logs et le formatage d'erreurs. La spec OpenAPI ne s'applique qu'aux endpoints REST.
Qu'est-ce qu'une approche API-first ?
L'approche API-first est une démarche de conception où l'API est traitée comme un produit à part entière, conçue et spécifiée avant tout développement applicatif. Concrètement, l'équipe rédige le contrat (généralement en OpenAPI) en amont, le fait valider par tous les consommateurs (front, partenaires, mobile, services internes), puis seulement après écrit le code côté serveur et côté client en parallèle. Bénéfices : parallélisation des équipes, contrats stables, tests dérivables de la spec, documentation toujours à jour. C'est l'inverse de l'approche code-first, où l'on écrit le code d'abord et où la documentation est générée a posteriori, souvent avec des écarts entre ce qui est documenté et ce qui est livré.
OpenAPI vs Swagger : quelle différence ?
Swagger était à l'origine (2011) à la fois une spécification et un ensemble d'outils créés par SmartBear. En 2015, la spécification a été donnée à la Linux Foundation et renommée OpenAPI Specification (OAS). C'est aujourd'hui le standard officiel, maintenu par l'OpenAPI Initiative (voir la structure de gouvernance). Le nom Swagger désigne désormais uniquement la suite d'outils de SmartBear (Swagger UI, Swagger Editor, Swagger Codegen). En résumé : on écrit une spec OpenAPI ; on la visualise avec Swagger UI. Les deux termes restent souvent utilisés de manière interchangeable dans le langage courant, mais la distinction est utile en contexte technique précis.
Comment versionner une API REST en production ?
Trois stratégies dominent, avec des compromis distincts :
- Versioning par URL (ex. /v1/devices, /v2/devices) : le plus visible et le plus simple à router. Inconvénient : couplage fort entre la version et l'URI, ce qui complique les redirections et la coexistence.
- Versioning par header (ex. Accept: application/vnd.kaizen.v2+json) : propre du point de vue REST, l'URI reste stable. Inconvénient : moins explorable, plus difficile à tester dans un navigateur.
- Versioning par paramètre de requête (ex. ?api-version=2.0) : souvent utilisé chez Microsoft / Azure, simple à mettre en place. Inconvénient : pollue les logs et les analytics.
Recommandations transverses : adopter le SemVer côté spec OpenAPI (MAJOR.MINOR.PATCH), ne jamais introduire de breaking change sans bump majeur, publier une politique de dépréciation explicite (par ex. 12 mois de support sur la version N-1), et automatiser la détection des breaking changes en CI (outils : oasdiff, openapi-diff). Sur notre projet, nous utilisons le versioning par paramètre de requête (héritage de l'écosystème Azure) avec un bump majeur sur la spec à chaque rupture de contrat.
Pour aller plus loin
A propos de l'auteur
Anaïs ALEX est Responsable du pôle Software chez Kaizen Solutions. Ingénieure diplômée de Grenoble INP - Phelma (spécialité Signal, Image, Communication, Multimédia), elle cumule près de 10 ans d'expérience en développement logiciel, avec un fil rouge marqué : l'IoT et l'exploitation de données capteurs.
Avant de rejoindre Kaizen, elle a été Lead Tech Full Stack chez TiHive (imagerie THz), Software Developer chez Thales sur des systèmes industriels embarqués, et Responsable développement logiciel et IA chez Morphosense, où elle a piloté des projets de Machine Learning sur séries temporelles et images issues de capteurs. Côté stack, elle évolue principalement en .NET Core, Python, Azure et architectures micro-services.
Ce REX est issu d'un lunch Data & Software qu'elle a présenté en interne chez Kaizen Solutions en 2025. Il décrit une mise en œuvre réalisée par l'équipe KAIZEN Solutions sur un projet IoT industriel.
Retour aux articles