Début 2020, un projet DevOps a été initié chez un de nos clients pour répondre à plusieurs besoins. Nous sommes dans un contexte où l’équipe d’exploitation (Ops) gère un grand nombre d’applications métier très hétérogènes avec un scope de responsabilités assez vaste, allant des facilities (gestion des salles serveurs), du provisionnement de serveurs virtuels (VMs,) jusqu’au déploiement des applications en production, en intégrant évidemment le monitoring applicatif, le stockage SAN, le backup disques/LTO7.
Les processus en place n’étaient plus suffisamment efficients et les demandes d’hébergement, de déploiement en production grandissant, il fallait repenser certaines méthodes de travail. Cette perte d’efficacité était en quelque sorte liée au turn-over régulier dans l’équipe d’Ops scope d’intervention mais aussi et surtout, au manque de dialogue avec les (nombreuses) équipes de développeurs.
La première phase de ce projet a été de faire en sorte que l’equipe des Ops adopte la méthodologie DevOps (mais surtout GitOps) pour la faire gagner en agilité, afin de pouvoir ensuite migrer sur une architecture résiliente et automatisée.
La phase suivante a été de reprendre les processus d’exploitation de l’infrastructure legacy et de trouver la meilleure solution qui s’offrait pour répondre à tous les besoins du client.
A partir de là, le choix s’est rapidement porté sur la solution  Kubernetes
Kubernetes
Dans cet article, nous allons expliquer ce choix et présenter les problématiques rencontrées sur sa mise en place dans l’infrastructrure on premise du client.
Choix de la solution Kubernetes
A quels besoins Kubernetes permet-il de répondre et à quelles contraintes s’expose-t-on dans un environnement on premise ?
Kubernetes est avant tout une solution open source initiée par Google pour orchestrer énormément de conteneurs en interne, puis le projet a été ouvert et est vite devenu une référence du catalogue de la CNCF (Cloud Native Computing Fundation). Ce qui fait la force de cet outil, c’est la possibilité de créer un cluster sur des hôtes qui soient on premise (datacenters internes à l’entreprise) ou dans tous les types de cloud-computing.
Kubernetes est maintenant bien connu et cette notoriété se distingue facilement lorsqu'on se penche sur les différents services managés, proposés par les principaux fournisseurs de Cloud du marché actuel (EKS chez Amazon, AKS chez Azure, GKE chez Google). De plus en plus d’entreprises migrent vers ce type d’infrastructure et les profils sur le marché de l’IT sont de plus en plus recherchés pour assurer le Build & Run autour de cette solution.
La communauté GitOps autour de Kubernetes est très active, tout comme la fréquence des sorties de versions :
| TIP |
– une majeure tous les 3 mois
– une mineur tous les mois |
| WARNING |
– une majeure tous les 3 mois
– une mineur tous les mois |
En introduction, nous soulignions le fait que les processus en place dans l’équipe d’Ops nétaient plus assez efficients en comparaison du nombre de demandes et qu’il manquait une certaine « agilité ».
Les mécanismes internes de Kubernetes, s’ils sont bien utilisés et en respectant la démarche DevOps, doivent normalement permettre de palier à plusieurs de ces difficultés…à condition d’avoir une équipe d’Ops qui soit suffisament bien dimensionnée mais surtout bien qualifiée !
C’est pourquoi dans notre contexte client, pour accélérer la montée en compétence de l’équipe, un mentor DevOps avec une expertise avancée de Kubernetes | Helm | IaC (Infrastructure As Code) a été détaché directement dans l’équipe d’Ops.
Le client avait plusieurs besoins initiaux :
- Conserver les données en interne
- Maîtrise des coûts liés à l’infrastructure
- Améliorer la fréquence et la qualité des déploiements des applications métier via pipelines CI/CD
- Résilience accrue des applications (qu’on peut obtenir grâce à Kubernetes avec le self-healing, liveness/readyness…)
- Rendre les équipes de développeurs plus autonomes
- Conteneuriser ce qui peut l’être et repenser les applications en micro-service
- Faciliter la gestion de l’infrastructure et des OS liés au contexte client
- Décrire l’infrastructure As Code
- Mutualiser les bonnes pratiques entre les Dev et les Ops
Avoir la gestion complète d’un cluster Kubernetes sur un environnement on-premise est bien différent d’un cluster Elastic Kubernetes Service (EKS) chez Amazon AWS par exemple. Avec AWS, le déploiement d’un cluster est simplifié au maximum et vous n’avez pas à vous préoccuper du control-plane contenant les masters-nodes. Tout est géré par les équipes IT d’Amazon AWS.
Sur une infrastructure on-premise, il faut
gérer l’installation et le déploiement complet du cluster, d’où
l’importance d’avoir des équipes d’Ops qualifiées, avec une bonne
connaissance des mécanismes et des composants internes de Kubernetes .
Voici les principaux composants d’un cluster Kubernetes :
| Etcd | Base clé/valeur qui stocke les données d’état du cluster, elle est généralement déployée en mode cluster sur les nœuds du control-plane. |
| Kube-scheduler | Contenu de la cellule |
| Ligne 3 | Contenu de la cellule |
| Ligne 4 | Contenu de la cellule |
Infrastructure As Code
Cette phase du projet a été cruciale car il fallait absolument être capable de déployer (ou de redéployer) un cluster Kubernetes en quelques minutes,
chose inenvisageable à la main car il y a trop de sources d’erreur, manque de reproductibilité…
La société HashiCorp en a fait son businness en proposant notamment deux outils libres et open source, capables de déployer de l’infrastructure à partir de fichiers descriptifs :
Un troisième outil libre et open source a été utilisé pour faire de la gestion de configuration soit pour provisionner des fichiers sur les machines, soit pour modifier la configuration des OS, démarrer des services avec systemD ou encore installer des paquets YUM :
Un troisième outil libre et open source a été utilisé pour faire de la gestion de configuration soit pour provisionner des fichiers sur les machines, soit pour modifier la configuration des OS, démarrer des services avec systemD ou encore installer des paquets YUM :
Pour faciliter la bonne tenue des objectifs et conserver une organisation efficace sans cadre figé, des limites WIP (Work in Progress) sont fixées. Le principe ? Limiter le travail en cours : une tâche par développeur (voire moins pour qu’il y ait toujours quelqu’un de disponible pour une revue de code) et tant que cette tâche n’est pas terminée, la personne ne passe pas à autre chose. L’objectif est tout simplement de finir ce qui a été commencé. Si les équipes ne parviennent pas à rester en dessous du WIP, alors c’est qu’il est temps de programmer un moment d’échange pour corriger le processus.
Remplir le pipe régulièrement permet de résoudre ce problème de rythme saccadé mais aussi de reprioriser certaines tâches grâce à une meilleure visibilité. Puisque le cloisonnement entre les itérations n’existe plus, il est en effet plus simple d’optimiser les tâches. Bien entendu, il est nécessaire de veiller à la bonne productivité de l’équipe. C’est en effet l’un des travers de Scrumban : avoir l’impression d’avoir plus de temps pour réaliser chaque tâche et tomber dans une sorte de perfectionnisme qui peut nuire au projet global. Pour pallier ce problème, il est important que les tâches soient découpées en sous-tâches et que le temps soit estimé pour éviter les dérives.
A quoi servent-ils respectivement ?
| Packer |
Terraform |
Ansible |
| Il est utilisé pour la création d’images immuables multi-plateformes (templates de VMs). |
Il permet aux Ops de prédire de manière certaine, la création, le changement et l’évolution de l’infrastructure via du code versionné. |
Les playbooks et les rôles Ansible servent à provisionner les fichiers de configuration ou les fichiers système. |
Ce qui fait la force de ces outils, c’est l’utilisation des API REST pour dialoguer avec les infrastructures et sont donc compatibles avec pratiquement tous les providers du marché (VMware, AWS, OpenShift…).
Le gros avantage de ces outils orientés GitOps, c’est justement l’utilisation de Git et le fait de bénéficier d’un système de branching et de versionning. Tout le code qui décrit notre infrastructure Kubernetes est alors stocké dans le GitLab hébergé en interne.
Dans notre contexte client, l’infrastructure en place repose sur un cluster constitué de 10 hôtes ESXi VMware vSphere 6.7, la rendant compatible avec ces trois outils.
Architecture du cluster client
Le cluster du client a été déployé avec kubeadm et en respectant les bonnes pratiques de la documentation Kubernetes :
 cluster_k8s
cluster_k8s
Tout le travail d’IaC effectué en amont avec la stack | Packer | Terrraform | Ansible | nous a permis d’avoir un cluster qui se déploie et s’initialise en quelques minutes seulement.
Bien entendu, pour que tout cela fonctionne, nous avons été obligés d’intégrer plusieurs éléments importants dans nos templates de VMs Packer :
- l’installation via YUM des binaires
docker, kubelet et kubeadm dans /usr/local/bin
- les certificats SSL ainsi que les autorités de certification du client (Root CA) dans /etc/pki/tls/certs/
- les scripts Bash et les clés SSH
- les différents fichiers de configuration (kube-config, calico…)
Gestion des registry Docker / Helm
Le contexte client impliquait l’abscence d’accès direct à Internet sur l’ensemble de l’infrastrcuture. Il a donc fallu récupérer toutes les images Docker nécessaires à la création du cluster Kubernetes et aux Charts Helm dans un espace GitLab prévu à cet effet.
Cette fonctionnalité intégrée à GitLab est connue sous le nom de shared-registry. Elle s’active au sein d’un projet GitLab et est ensuite accessible sur le port 5050.
Utilisation de la shared-registry pour nos images Docker :
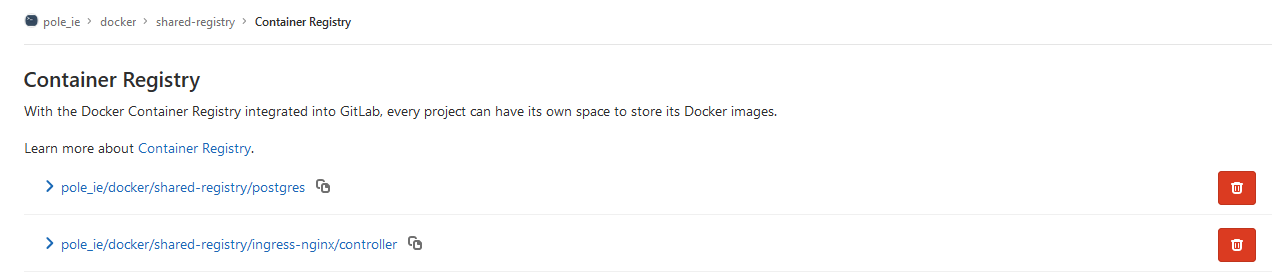 registry_dockers
registry_dockers
Docker login :
class="wp-block-syntaxhighlighter-code">docker login gitlab.client.local:5050
Docker build / push :
class="wp-block-syntaxhighlighter-code">docker build -t gitlab.client.local:5050/pole_ie/docker/shared-registry .
docker push gitlab.client.local:5050/pole_ie/docker/shared-registry
Le même procédé a été utilisé pour stocker nos Charts Helm :
 registry_dockers
registry_dockersHelm registry login :
class="wp-block-syntaxhighlighter-code">helm registry login gitlab.client.local:5050
Helm save / push :
class="wp-block-syntaxhighlighter-code">cd charts/<chart name>
helm chart save . gitlab.client.local:5050/pole_ie/helm-charts/<chart name>:<chart version>
helm chart push gitlab.client.local:5050/pole_ie/helm-charts/<chart name>:<chart version>
Connexion aux clusters
Une fois que le cluster s’initialise, on récupère les tokens d’admin sur un des noeuds master du control-plane, puis on le place sur notre poste de travail dans notre home_directory .kube/.
| Warning |
Attention, cette manière de faire n’est pas une bonne pratique.
Il faut mettre en place une solution d’authentification pour les utilisateurs. |
L’idéal est d’avoir une solution d’authentification sur l’annuaire de l’entreprise (OIDC, SAML…etc).
Dans notre contexte, chaque fichier correspond à un cluster Kubernetes (test, dev, prod) .
Cette configuration permet de « switcher » rapidement d’un cluster à un autre par l’intermédiaire du binaire kubectl :
class="wp-block-syntaxhighlighter-code">❯ grep -ri "KUBECONFIG" ~/.zshrc
export KUBECONFIG=$KUBECONFIG:$HOME/.kube/production:$HOME/.kube/development:$HOME/.kube/sandbox
Avec l’aide d’alias, on peut alors lister ou utiliser les différents contextes disponibles (donc changer de cluster)
class="wp-block-syntaxhighlighter-code">❯ kcgc
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* dev development kubernetes-admin argocd
kubernetes-admin@kubernetes kubernetes kubernetes-admin monitoring
prod production production-admin argocd
❯ kcuc prod
Switched to contexte "prod".
❯ kcgc
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
dev development kubernetes-admin argocd
kubernetes-admin@kubernetes kubernetes kubernetes-admin monitoring
* prod production production-admin argocd
Déployer avec Argo CD ! 
Au début du projet, les applications étaient déployées dans Kubernetes via des Charts Helm depuis nos postes de travail respectifs, à l’aide du binaire Helm dans sa version 3.
La tâche était assez laborieuse car il fallait d’abord configurer nos postes de travail, se souvenir du nom de la Chart, dans quel repo Git elle se trouve, se synchroniser sur la bonne branche…
De plus, nous n’avions pas directement la possibilité de connaître le dernier état dans lequel s’était déployée la Chart Helm.
Exemple de déploiement d’une Chart Helm à la main :
Configurer la variable HELM_EXPERIMENTAL_OCI
class="wp-block-syntaxhighlighter-code">export HELM_EXPERIMENTAL_OCI=1
Ajout du repo Helm :
class="wp-block-syntaxhighlighter-code">helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
Premier déploiement :
class="wp-block-syntaxhighlighter-code"># Met à jour les dépendances
helm dep up
# Déploie la chart
helm install --namespace <namespace> <chart-name> . -f values.yaml -f values.<env>.yaml -f secrets.<env>.yaml
Mise à jour de la Chart :
class="wp-block-syntaxhighlighter-code">helm upgrade -i --namespace ingress-controller ingress-nginx . -f values.yaml
Voir les différences entre deux mises à jour de Charts :
class="wp-block-syntaxhighlighter-code">helm diff upgrade --namespace ingress-controller ingress-nginx . -f values.yaml
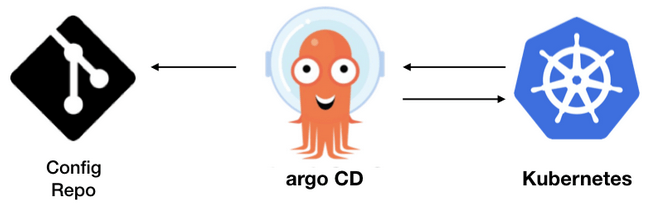
Heureusement, un nouvel outil est apparu dans le catalogue de la CNCF et vient largement simplifier les déploiements dans Kubernetes.
Il se fait connaitre sous le nom de Argo CD !
Il simplifie tout ce qui a été mentionné ci-dessus et permet de se concentrer uniquement sur les processus de déploiements.
Argo CD ne remplace en aucun cas des outils comme Jenkins, mais propose via une interface web intuitive, une vue en temps réel sur l’état de santé des applications déployées.
Il détecte ce qui a changé par rapport aux derniers commits et exécute un flux de synchronisation qui déploie automatiquement les changements sur le(s) cluster(s) Kubernetes.
 Argo CD
Argo CD
Il a le gros avantage d’avoir été pensé « As Code« , c’est à dire qu’on peut le configurer directement via une Chart Helm de façon à ce qu’il soit Up & Ready dès qu’il est déployé dans le cluster.
De plus, on peut très bien disposer d’une instance Argo CD Master qui déploie ensuite une autre instance Argo CD !
What ??? Mais pourquoi faire ?! ?
Cette méthode permet de couvrir plusieurs cas d’usage :
- un nouveau cluster est déployé sur l’infra, on peut alors « piloter » les déploiements depuis l’instance Argo CD Master
- bénéficier d’instances auto-gérées
Sa principale force réside dans le fait de pouvoir se sourcer directement sur des repos Git pour détecter immédiatement les changements d’états des projets déployés.
Le changement d’état est visuel et la validation humaine se fait d’un simple clic sur le bouton « Sync« .
Avant de valider, il est bien sûr possible d’afficher les changements sous la forme d’un git-diff, qui revient à faire un helm diff upgrade lorsqu’on déploie à la main.
Pipelines CI/CD 
La méthodologie DevOps implique que des règles communes entre Dev et Ops soient définies en avance de phase de manière à ce que tout le monde soit raccord sur la façon de travailler.
Dans ce contexte, nous avons défini des règles de déploiement qui s’articulent de la manière suivante :
| Warning |
| Il est indispensable de créer un fichier de values pour chaque environnement à déployer, à la racine de la chart Helm |
class="wp-block-syntaxhighlighter-code">values.yaml (contient les valeurs communes à tous les environnements)
values.dev.yaml
values.integration.yaml
values.recette.yaml
values.preproduction.yaml
values.production.yaml
Toute autre fichier de values qui ne respecte pas cette nomenclature fera échouer le job ou ne sera pas pris en compte.
Chaque équipe de développement est autorisée à déployer des namespaces avec la convention de nommage suivante :
class="wp-block-syntaxhighlighter-code">project-dev
project-integration
project-recette
project-preproduction
class="wp-block-syntaxhighlighter-code">project
Les jobs de déploiement sont déclarés dans un noeud Jenkins à l’intérieur d’une multi-branch pipeline en Groovy.
Le serveur Jenkins principal fait appel à un agent Jenkins présent dans un namespace Kubernetes. Cet agent se connecte à un repo GitLab interne sur la bonne branche, puis exécute les différents steps Helm comme si on déployait une Chart manuellement :
class="wp-block-syntaxhighlighter-code">helm registry login
helm dependency update
helm diff upgrade
helm upgrade -i
class="wp-block-syntaxhighlighter-code">String environment = ENV
String namespace = "${PROJECT}-${environment == 'development' ? 'dev' : environment}"
boolean humanValidation = Boolean.parseBoolean(HUMAN_VALIDATION)
podTemplate {
node('jenkins-agent-pole-ie') {
stage('Checkout repository'){
checkout([
$class: 'GitSCM',
doGenerateSubmoduleConfigurations: false,
extensions: [],
branches: [
[name: BRANCH],
],
userRemoteConfigs: [[credentialsId: 'jenkins-gitlab-registry-dev', url: REPOSITORY_URL]]
])
}
container('helm') {
stage("Helm dependency update") {
withCredentials([
usernamePassword(credentialsId: 'jenkins-gitlab-registry-dev',
usernameVariable: 'username',
passwordVariable: 'password')
]) {
sh "helm registry login gitlab.client.local:5050 -u '${username}' -p '${password}'"
}
sh "cd ${CHART_PATH}; helm dependency update"
}
stage("Generate Helm Diff"){
sh "cd ${CHART_PATH}; helm diff upgrade --allow-unreleased --namespace ${namespace} ${PROJECT} . -f values.yaml -f values.${environment}.yaml"
}
stage("Validate Deployment - Waiting for Human validation") {
if (humanValidation) {
input(message: "Check Helm diff. Do you want to proceed to the deployment ?")
}
}
stage("Deploy the application"){
sh "cd ${CHART_PATH}; helm upgrade -i --namespace ${namespace} ${PROJECT} . -f values.yaml -f values.${environment}.yaml"
}
}
}
}
Et comment on monitore ? 
Maintenant qu’on a vu comment était déployées les applications au sein du cluster, intéressons nous à l’observabilité de celles-ci.
C’est une brique importante, surtout lorsque les premières applications arrivent en production.
Le monitoring dans Kubernetes peut être déployé rapidement, mais il faudra y consacrer beaucoup de temps pour obtenir quelque chose de robuste et fiable.
Tout le monde connait des outils de monitoring basés sur le protocole SNMP, tels que [Centreon] ou [Nagios] et il est d’ailleurs possible de monitorer un cluster Kubernetes via des plugins payants.
Il est cependant préférable d’utiliser des outils prévus à cet effet. Kubernetes expose un nombre incalculable de métriques à travers son api-server.
Ces métriques peuvent donc facilement être envoyées dans un exporter Prometheus et être affichées à travers des graphiques proposés par Grafana.
Un projet GitHub nommé kube-prometheus-stack permet d’avoir toute la stack « Monitoring » dans un cluster Kubernetes.
Elle se compose de plusieurs éléments :
Prometheus donne la possibilité de personnaliser des règles à partir des métriques qu’il récupère via l’API Kubernetes.
Par exemple, si on veut vérifier l’état des Ingress dans un namespace précis, c’est possible. Il faut connaître le nom de la métrique et jouer ensuite avec les opérateurs :  Prometheus
Prometheus
Grafana permet de gérer l’affichage des données qui lui sont transmises via une datasource (Prometheus, InfluxDB…).
Dans la Chart kube-prometheus-stack, tous les dashboards utiles à Kubernetes sont déjà présents.
Il suffit d’attendre qu’un certain nombre de données soit collecté pour que les dashboards soient alimentés.  Argo CD
Argo CD
Quant à Alertmanager, il intercepte les dépassements de seuils pour les transformer en alertes puis envoie les notifications via des receivers (mails, webhooks Slack, Teams…etc).
Alertmanager intègre aussi des règles d’alerting déjà prévues pour Kubernetes mais il faut avoir en tête qu’un alerting efficace est un alerting qui couvre les principaux types de pannes sur une application en production.
- restart de pods
- pods en CrashLoopBackOff
- healthcheck sur les URLs exposées par les ingress
Conclusion
Le démarrage du projet a été compliqué car l’équipe des Ops partait de zéro et n’était pas formée aux méthodes de travail induites par tous ces nouveaux outils.
- La courbe d’apprentissage liée à Kubernetes | Helm est assez longue et complexe.
- Un renforcement de l’équipe et une montée en compétences a été nécessaire.
- La stratégie de l’équipe a été repensée pour mieux répartir la charge de travail entre Build & Run et la transformation DevOps
En dépit de ces difficultés et grâce à l’implication de chacun, plusieurs applications métier ont déjà été migrées dans les clusters Kubernetes hors-production du client.
Une des étapes importante du projet à été la mise en production de la première application du client au mois de Juillet 2021.
Depuis, les déploiements en Production se sont poursuivis et l’équipe dispose d’une roadmap conséquente pour venir améliorer la robustesse des clusters.
Retour aux articles