Problématique
On entend régulièrement, par exemple lors d’entretiens d’embauche, demander d’expliquer la différence entre Statistiques et Data Science. La question s’avère intéresser un grand nombre de personnes dans le monde de l’informatique, au sens large, et chacun y va de son avis. Nous n’allons pas trancher définitivement, mais plutôt étayer de plusieurs façons comment différencier ces deux disciplines.
Méthodologie
Il paraît évident que les Data Sciences1 ne sont pas tout à fait des statistiques. Cependant, dès que l’on commence à expliquer pourquoi, si l’on n’a pas préparé le sujet, on va rapidement donner des exemples ou des concepts qui font appel à la statistique. Cela n’aide pas à clarifier la réponse : le terme Data Science n’est-il qu’une appellation ronflante et quel est le rôle - voire l’importance - des statistiques dans ces dites sciences des données ? Notre méthode va être de comparer les deux avec les critères suivants :
- Essai de définition de chaque discipline
- Vocabulaire et concepts
- Problèmes traités et types de données
- Approches et buts visés
- Techniques et compétences spécifiques
- Domaines d’application
- Métiers associés
On peut aussi faire la liste des logiciels ou progiciels utilisés par l’une ou l’autre des disciplines, nous renvoyons à la bibliographie pour ce point.
Pour illustrer cette démarche, nous utiliserons quelques problèmes qui peuvent s’apparenter à l’une ou l’autre des disciplines.
Problèmes-type
- Dans une ville donnée, est-ce qu’il pleut plus le dimanche que le lundi ?
- On a examiné 4600 pièces mécaniques issues d’une ligne de production, et on a trouvé un taux de rejet de 0.54%. On mesure sur chaque pièce, 48 paramètres durant le procédé de fabrication. Est-il possible d’anticiper, avec ces mesures ou un sous-ensemble de ces mesures, le fait que des nouvelles pièces seront conformes ou pas ?
- Le département Marketing & Sales d’une société demande un algorithme de décision, pour estimer le meilleur prix de vente à fixer pour maximiser les bénéfices sur la commercialisation future d’un nouveau modèle d’appareil high-tech. Pour cela on se fonde sur les données des ventes d’un modèle similaire sur les 5 dernières années, ainsi que d’autres données ou indicateurs socio-économiques, saisonniers et géographiques (prix de matières premières, cours de la bourse, taux de chômage, pays visés, catégories des clients, …).
- Usure de pneus : on a établi que pour un certain modèle de voiture, la distance à laquelle il faut changer les pneus avant bien approximée par une loi normale d’espérance mathématique valant 36500 km. Sachant que j’ai déjà parcouru 33000 km avec mes pneus, puis-je espérer en faire encore 5000 sans risque réel ?
Un examen rapide de ces problèmes permet normalement de les rattacher aux statistiques pures ou aux Data Sciences. Cependant nous verrons que ce n’est pas toujours si évident.
Que sont les statistiques et les Data Sciences ?
Les statistiques et les Data Sciences ont pour objet des jeux de données, constitués de valeurs quantitatives ou qualitatives, possiblement de nature mixte. Chacune de ces disciplines a pour but d’extraire de l’information ou du sens à partir de ces données, pour aider par exemple à la compréhension de phénomènes complexes ou à la décision.
Les statistiques en résumé
Les statistiques sont une science mathématique, qui utilise des techniques destinées à produire des informations/indicateurs résumant un jeu de données (tels que la moyenne ou l’écart-type) ou à trouver des relations entre des données de sortie et des paramètres d’entrée. On parle de statistiques descriptives.
Les statistiques inférentielles ( Inferential Statistics en anglais), quant à elles, sont principalement utilisées pour le test d’hypothèse, relativement à un jeu de données, avec une approche probabiliste. On obtient par exemple un résultat à partir d’un échantillon de faible taille (typiquement un sondage avant un vote) : le pourcentage obtenu va-t-il s’appliquer à la population toute entière ? Avec quel niveau de confiance ?
Le problème est une question de statistiques : si nous récupérons les données pluviométriques sur 10 ans (soit un échantillon d’environ 520 valeurs), dans un même lieu, nous pourrons certainement conclure avec un bon intervalle de confiance.
Le vocabulaire des statistiques
Dans le monde des statistiques, on rencontre souvent les termes suivants, utilisés pour l’analyse mathématique de données numériques :
- moyennes et médiane
- variance et écart-type
- moments d’ordre supérieur comme Skewness et Kurtosis
- corrélation, analyse par composantes principales (PCA)
- probabilités : lois diverses de distribution statistique, théorèmes central-limite
- test d’hypothèse
- intervalle, niveau de confiance
- approche fréquentielle ou Bayésienne
Les statistiques sont bien une partie des mathématiques, qui utilise parfois des algorithmes pour des calculs longs, mais dont l’objectif premier n’est pas la recherche et l’implémentation efficace de tels algorithmes.
Les Data Sciences : vers une définition
Les Data Sciences ne sont pas seulement un domaine des mathématiques appliquées, puisque par essence elles sont interdisciplinaires. Elles peuvent traiter des jeux de données gigantesques et hétérogènes, et contiennent diverses méthodes de préparation initiale des données. Ainsi les algorithmes de partitionnement sont un exemple d’organisation des données.
Généralement, on parle de Data Science lorsqu’on cherche à apprendre à partir d’un ensemble de données, pour ensuite prévoir des résultats sur des données de même nature ; ceci peut entrer dans un process dynamique d’amélioration continue du modèle prédictif en fonction de nouvelles données analysées. Ce n’est pas une approche classique en statistiques.
Cependant les Data Sciences ont besoin des outils probabilistes et statistiques, ainsi que d’informatique car elles sont une science des algorithmes – comme le sont les méthodes d’optimisation par gradient pour calculer les meilleurs coefficients d’un modèle. L’apprentissage (Machine Learning) est considéré comme une partie des Data Sciences. La science des données est l’une des principales disciplines utilisées en Intelligence Artificielle, pour appréhender les problèmes de Big data. On ne peut dire que ce sont simplement des statistiques - appliquées à des quantités très importantes de données.
Notre problème est une question de Machine Learning :
- répartir les 4600 données de l’échantillon en un sous-ensemble d’apprentissage (learning set) et un second de validation (validation set) pour éprouver les modèles à tester.
- utiliser des méthodes de corrélation, pour extraire une ensemble de paramètres effectivement impliqués lorsqu’une pièce est rejetée.
- calculer et construire des modèles de prédiction de cette sortie binaire (conformité = 1, non-conformité = 0) à partir de ce sous-ensemble de données et de paramètres. Cela peut faire appel à un algorithme d’optimisation.
- sélectionner le modèle qui minimise les erreurs sur l’ensemble de validation.
- pour les nouvelles pièces produites, mesurer les paramètres significatifs uniquement et décider si la pièce va être conforme ou pas, grâce au modèle sélectionné.
Eléments de vocabulaire des Data Sciences
Un Data Scientist va fréquemment rencontrer ces termes ou ces concepts :
- Data Mining : analyse des données brutes pour extraire des relations entre données, trouver des figures significatives (patterns) et préparer le jeu de donnée au calcul du modèle
- Machine Learning : famille d’algorithmes plus ou moins sophistiqués, pour élaborer un modèle prédictif à partir d’un ensemble
- Apprentissage supervisé
- Intelligence Artificielle, IA
- Big Data
- Réseau neuronal ou de neurones
Les Data Sciences font partie de l’informatique (Computer Science), leur but est d’inventer ou de perfectionner des algorithmes effectifs d’analyse d’ensembles de données complexes, pour obtenir des modèles explicatifs, prédictifs et évolutifs. L’apprentissage (Machine Learning) est l’une des parties des Data Sciences les plus utilisées pour cet objectif. Les statistiques sont l’un des domaines mathématiques à connaître pour les Data Scientists.
L’importance des statistiques au sein des Data Sciences
Contrairement aux sciences déterministes comme la mécanique classique ou électricité, où des méthodes à base de systèmes différentiels permettent l’obtention de très bonnes prédictions, le champ d’application des Data Sciences impose le besoin d’outils statistiques ou probabilistes, pour obtenir/analyser l’information.
Les statistiques descriptives sont généralement insuffisantes pour obtenir ce genre de prédictions, ou elles ne sont tout simplement pas adaptées aux problèmes de Big Data par exemple. Cependant, le Data Scientist se doit de maîtriser de nombreux concepts relevant des statistiques : échantillonnage d’une population, principales lois de distribution, signification des indicateurs (exemple variance, covariance), connaissance de méthodes de régression pour relier des paramètres d’entrée à des sorties, interprétation des tests statistiques, intervalles de confiance.
Considérons une série chronologique (extension de la banquise en Arctique ):

Les commentaires et les données, dans cette illustration, sont des « objets » statistiques (tendance, moyenne mobile).
Ce graphique est similaire en apparence à la série associée au prix moyen mensuel du baril de pétrole (source : https://www.statista.com/statistics/262861/uk-brent-crude-oil-monthly-price-development/ ). Calculer une courbe ou une droite de tendance, pour le Data Scientist, est une façon statistique de proposer une prédiction simple du prix du pétrole dans cette situation, indépendamment de l’usage de modèles plus complexes utilisant des paramètres additionnels.

Ainsi la statistique est un domaine mathématique central pour le développement des Data Sciences. Son vocabulaire est utilisé constamment par les Data Scientists.
En quoi pourrait-on faire la confusion entre ces disciplines ?
Certaines personnes, même des développeurs, font parfois la simplification d’utiliser les termes Data Science ou statistiques comme si c’était la même chose.
Cette confusion est plus courante qu’il y a une dizaine d’années, car de nos jours de nombreux développeurs sont devenus des acteurs de la Data Science, sans connaître suffisamment les bases mathématiques de cette discipline. Il est possible de créer du code correct, comprenant des algorithmes de Machine Learning par exemple à l’aide de librairies en Python, sans réellement comprendre le contenu mathématique sous-jacent.
D’autre part, comme la littérature autour des Data Sciences, ainsi que de nombreux articles en ligne, contiennent beaucoup de termes, concepts et méthodes issus des statistiques, cela peut prêter à confusion.
Revenons sur des programmeurs de Data Science sans bases statistiques : on pourrait les dénommer utilisateurs de la Data Science, alors que les ingénieurs ou scientifiques qui développent des algorithmes de Data Science, en R, Python ou C++ pourraient être différenciés en les appelant des constructeurs de Data Science.
Enfin une autre façon de comprendre cette confusion provient problèmes où les deux approches sont appropriées. Un modèle par régression linéaire, pour prédire un comportement numérique (par exemple la productivité d’une céréale en fonction de la semence, de la pluviosité hebdomadaire, …) peut être obtenu après une étude statistique, mais être présenté par son auteur comme un beau problème de Machine Learning, pour apparaître plus brillant et plus à la mode.
Les différences principales
Les Data Sciences ne doivent pas être considérées comme une alternative équivalente à l’approche statistique. On peut les penser semblables, si on prétend simplement que chacune de ces disciplines sert à extraire de l’information à partir de données. Plusieurs auteurs ont défriché ce sujet (voir bibliographie et liens en annexe) et voici une synthèse des différences principales :
- Les statistiques sont un champ des mathématiques, alors que les Data Sciences ont une portée plus étendues, de par leur nature inter-disciplinaire.
- Les statistiques utilisent les données dans un mode relativement « passif », alors que les Data Sciences vont aller plus loin dans l’extraction de sens, ce qui signifient qu’elles sont destinées à traiter des données de nature hétérogène, et de trouver parfois des relations hors d’atteinte des méthodes statistiques : typiquement, des réseaux de neurones ayant parfois des dizaines de couches, en Deep Learning, ne font pas partie du domaine des statistiques.
- On utilisera des Data sciences pour découvrir, dans un ensemble complexe et volumineux de données, des figures ou des arrangements significatifs (patterns) et pour aider à la décision ; généralement on utilisera des méthodes statistiques pour des ensembles de données plus réduits, afin d’extraire des relations de cause à effet au sein des données.
- On fait aussi appel aux statistiques pour confirmer une hypothèse formulée a priori, tandis que les Data Sciences sont plus à même d’explorer les données: dans “Understanding Machine Learning – 2015, section 1.4”, S. Shalev-Shwartz et S. Ben-David précisent une nuance entre les statistiques inférentielles et l’apprentissage automatique (partie des Data Sciences) : ce dernier peut, en effet, discerner des figures nouvelles ou aider à formuler des hypothèses inédites, à partir du même jeu de données.
- L’une des tâches du Data Scientist est aussi de sélectionner le meilleur modèle de prédiction, parmi plusieurs algorithmes, en mesurant sa précision sur des ensembles d’apprentissage/validation prédéfinis. En ce sens, l’approche statistique est moins exploratoire.
- Les champs d’application de ces domaines sont différents. Ainsi, bien que l’analyse du langage naturel par les statistiques existe, l’approche par IA est plus adaptée et donne de meilleurs résultats. Inversement, les modèles statistiques avancés sont un outil efficace en analyse financière, par exemple pour étudier les cours des actions.
Introduire de l’IA dans un ERP n’est pas une méthode statistique, alors que les Data Sciences pourraient permettre d’identifier quelles opérations améliorer par des algorithmes intelligents au sein d’une entreprise (Business Intelligence). - Il faut noter une différence mineure concernant la présentation des données, qui est relativement stable du côté des statistiques, alors que c’est devenu un vrai sujet avec l’émergence des Data Sciences : la Data Visualization.
Voici un tableau récapitulatif de certaines différences :
| Data sciences | statistiques |
| Utilisation d’algorithmes programmés, pour aider à la décision sur n’importe quel jeu de données | Améliorer l’analyse et la compréhension d’un jeu de données par des concepts mathématiques |
Identifier des tendances mais aussi des combinaisons significatives (patterns)
| Liens de cause à effet entre paramètres explicatifs et observations |
| Capable d’appréhender les données massives (Big Data) | Travaille sur des ensembles de données moins grands |
| Source de données mixtes (qualitatives et quantitatives) | Sources de données homogènes |
Optimisation de modèles, recherche dans plusieurs familles de modèles
| Méthodologie plus statique pour la décision |
Secteurs d’application variés :
Détection
Imagerie
Santé
Langage naturel | Secteurs d’application plus ciblés :
Démographie
Indicateurs économiques
Banque
Etudes biologiques |
Comparaison de ces approches sur nos exemples
On peut raisonnablement prendre comme principe général, que la meilleure approche est celle qui est la plus simple, à résultats équivalents. Illustrons ceci avec nos problèmes-type.
- Est-ce qu’il pleut plus les lundis que les dimanches ?
Ceci peut concrètement se présenter ainsi : sur 10 ans, j’ai récolté 520 données. Il me suffit de compter les nombres x1 de lundis pluvieux et x2 de dimanches pluvieux. De manière presque certaine, x1≠x2. Puis-je pour autant conclure ? Supposons que x1=130 et x2=161. Le statisticien va tester l’hypothèse x1<x2 pour un effectif de 520. En aucun cas cela ne nécessite une approche par Data Sciences. Un Data Scientist ne saurait proposer de meilleure réponse que cette approche descriptive et inférentielle du problème.
- Prédire un taux d’erreur de fabrication, à partir d’un échantillon de 4600 données, comprenant chacune 50 paramètres numériques.
L’approche statistique consiste à trouver une relation entre les valeurs des paramètres des pièces défectueuses, par rapport à ceux qui sont conformes. Dans les bonnes situations, les pièces défectueuses vont donner lieu à des configurations observables facilement, par exemple sur quelques indicateurs statistiques, pour un nombre restreint des paramètres mesurés. L’approche des Data Sciences (Machine Learning avec SVM ou CNN) permet d’aller plus loin, en extrayant automatiquement quels paramètres sont significatifs et quelles combinaisons numériques vont donner lieu à des défauts. On peut espérer une meilleure capacité prédictive des Data Sciences dans ce cas.
- Un algorithme pour prévoir le meilleur prix pour un nouveau modèle de téléphone mobile, en utilisant divers paramètres du marché.
Cette question demande d’abord de définir quelles données exploiter. Quels sont les indicateurs du marché, comment les récupérer sur Internet ou autre, doit-on acheter des séries statistiques ? Ensuite, comment mettre en œuvre un algorithme d’acquisition des données, ainsi qu’un algorithme dynamique de calcul de prix, à exécuter périodiquement ? Il peut y avoir des millions de données à trier, analyser, modéliser. Des informations qualitatives comme des extraits de presse économique (RSS feed) peuvent avoir un impact. Ce n’est donc pas un sujet de statistique pure, et les Data Sciences paraissent mieux armées pour traiter une telle problématique.
- Est-il nécessaire que je change mes pneus après 38000km, sachant que la distance moyenne avant usure est de 36500km ?
Nous avons là un pur problème de statistiques mathématiques. La loi Normale donne la probabilité que les pneus soient trop usés après 38000km. On en déduit le risque encouru à ne pas les changer.
Evidemment, on peut tenter une approche plus explicative par les Data Sciences, en étudiant les paramètres conduisant à la loi d’usure d’une voiture particulière : profil du conducteur, éléments climatiques, type de routes utilisées. Cela pourrait améliorer la précision de la prévision de l’usure des pneus.
Le schéma qui suit résume les interactions entre les différents domaines abordés :
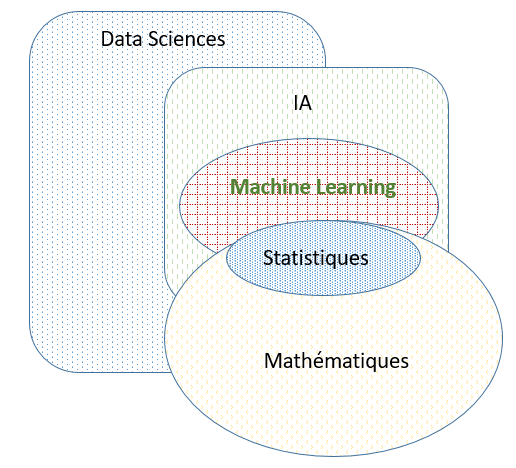
Le métier de statisticien
Certains ingénieurs ou scientifiques de formation se posent la question de travailler en tant que Statisticien ou Data Scientist. Ces deux métiers demandent plusieurs années d’études, pour maîtriser le socle minimal de mathématiques nécessaires ; ensuite, le métier envisagé dépend de l’appétence pour la partie plus mathématique et calculatoire, ou la partie programmation et algorithmique, combinée au goût pour la résolution de problèmes techniques usuels en informatique : débogage, problèmes de connexion, sécurité des données …
Il ne suffit pas de préférer Python à R ou SAS, pour décider de devenir Data Scientist. Concrètement, je pense que certains ingénieurs peuvent devenir de bons Data Scientists mais ne pourraient pas travailler en tant que Statisticiens car ils n’auront pas le niveau ou la patience mathématique nécessaire.
Actuellement, depuis l’émergence du Big Data, beaucoup de sociétés ont plus de besoins de compétences en Data Science qu’en statistiques pures. On peut faire une analogie avec, dans le domaine du logiciel, l’évolution des anciens rôles de programmeur et d’ingénieur systèmes en un seul rôle d’ingénieur DevOps : ainsi, un département d’Analyse de Données préfèrera embaucher un Data Scientist plutôt qu’un mathématicien (supposé peu formé en utilisation professionnelle de l’informatique).
De même pour devenir chercheur, y compris dans un département de Statistiques, le futur docteur devra suivre des cours de Data Science : https://pll.harvard.edu/subject/data-science
Les métiers de la Data Science
Depuis l’éclosion de cette discipline, plusieurs métiers ont émergé, nous pouvons les organiser en quatre fonctions principales :
- Data Analyst, Data Manager : acquisition et mise en forme des jeux de données, stockage à partir de données brutes, sécurisation
- Data Engineer, Data Scientist : donner du sens aux données, modéliser et prédire, gestion des données massives du Big Data
- Data visualization : représenter les données brutes ainsi que les informations extraites, à l’aide d’outils spécifiques, Business Intelligence
- Management : data product owner (chef de projet digital) ou chief data officer (directeur de stratégie digitale)
| MÉTIER / FONCTION | Tâches, responsabilités | Outils |
| Data Analyst | Acquisition et mise en forme des données, collecte, stockage, validation | Data mining |
| Data Engineer/Scientist | Modélisation, prédiction, innovation
| IA, Machine learning, Cloud |
| Data Visualization | Mise en forme des résultats | Dataviz, Cloud, Power BI |
| Chief Data Officer | Stratégie data, architecture, fonction transverse | |
On le voit, ce ne sont pas des métiers de la statistique. Cependant les rôles de management sont pour moi une évolution des fonctions classiques de chef de projet informatique ou directeur de projets, qui interviennent dans le monde des données.
Notons que les Data Sciences ne s’apprennent pas en quelques années d’études, mais nécessitent de l’expérience, en confrontant ses connaissances avec des sujets réels, dans différents domaines d’applications. C’est cette expérience qui permet de bien comprendre cette discipline et de savoir mieux sélectionner quelle approche utiliser en fonction du problème rencontré.
Conclusion
On rencontre souvent des problèmes où les Statistiques et les Data Sciences donnent des résultats similaires. Nous considérons cependant que ce n’est pas une bonne façon de les comparer. Les véhicules thermique et électrique sont similaires, alors que les Statistiques et les Data Sciences ne peuvent se comparer si directement, l’une étant utilisée par l’autre.
Nous avons souligné les différences principales entre les Statistiques et les Data Sciences : ces dernières comprennent nettement plus d’algorithmique et de connaissances des systèmes informatiques de gestion ou d’acquisition des données, tout en s’appliquant à des secteurs inabordables par les Statistiques pures.
Cependant – concernant ce débat - la question reste pertinente et les avis partagés.
Annexe : liens utiles
- Sur les statistiques inférentielles et descriptives
- Définition des Data Sciences
- Rôle des statistiques dans les Data Sciences
- Différents types de données
- Différences principales entre Data Sciences et Statistiques
- Métiers de la Data Science
1Le terme littéral « Science des données » n’est pratiquement pas utilisé par la communauté française ; on le rencontre parfois dans des articles écrits par des canadiens ou des québécois.
Retour aux articles