Le but de cet article est de décrire, dans les grande lignes, une interprétation du cycle de vie d'un projet de Machine Learning. La description que nous allons en donner n'est pas unique, notamment le découpage en "étapes" mais permet de rendre explicite le déroulement d'un tel projet.
Machine Learning & Data Science quelle différence ?
Tout d'abord clarifions ce qu'est la DataScience (ou Science des données). On peut la définir comme la rencontre de plusieurs disciplines :
- mathématiques (statistique et analyse de données, algèbre linéaire),
- de l'informatique (apprentissage automatique, "Machine Learning" et intelligence artificielle)
- des technologies de l'information (internet, télécommunications).
Elle a pris son essor depuis le début du XXIème siècle avec l'augmentation des capacités de calcul des ordinateurs ainsi que de la volumétrie des données ("Big Data") à traiter et valoriser avec le développement croissant d'internet. L'utilisation du mot "Science" provient du fait que l'exploitation et la valorisation d'un ensemble de données s'effectue en suivant la méthode scientifique: recueil d'observations, formulation d'hypothèses/modélisation, tests puis confirmation/infirmation des hypothèses.
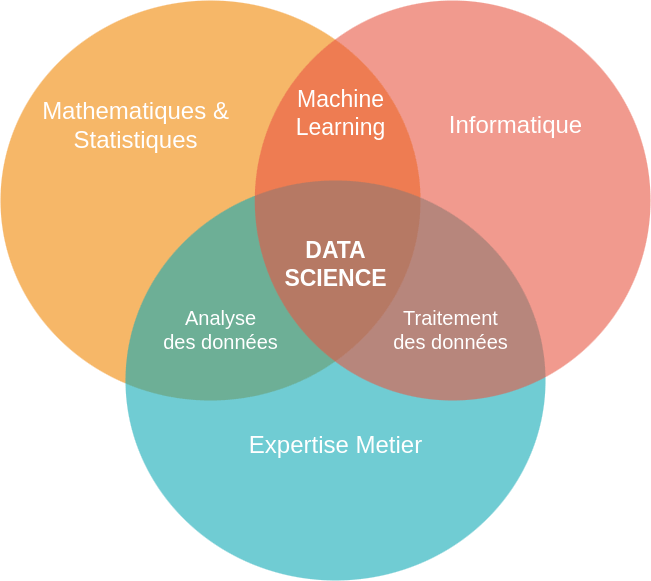
Ce processus est cyclique jusqu'à obtenir un accord/lien entre les observations et les hypothèses qui sera reproductible lors de l'ajout de nouvelles données. L'accord et le lien entre les hypothèses et les observations seront quantifiés et validés à l'aide d'un autre aspect crucial dans la science des données : la connaissance et l'expertise du domaine concerné par les données à analyser. Dans un processus d'apprentissage supervisé cela permettra notamment "d'encapsuler" les connaissances métier dans un modèle prédictif de machine learning.
Le Machine Learning représente donc la partie de développement d'un modèle d'apprentissage à partir d'un ensemble de données. Un projet de Machine Learning à partir de besoins et d'objectifs bien définis et quantifiables pourra aider à la prise de décision, conduire à une meilleure efficacité et d'optimiser la gestion de projet ou encore de valoriser des données de clients. Un projet de DataScience peut être vu quant à lui comme le processus global de mise en production du projet de Machine Learning.
Le workflow d'un projet de Machine Learning
Comme mentionné dans le paragraphe précédent, un projet de Machine Learning est un processus cyclique que l'on peut décrire par 8 grandes étapes. Chaque étape peut en influencer/remettre en question une autre, la finalité étant de fournir une réponse statistiquement robuste vis-à-vis d'une problématique initiale.
Le découpage que nous proposons en 8 étapes n'est pas unique et peut être sujet à discussion, notamment car chaque étape est interconnectée avec les autres. Cependant, cela permet de rendre explicite le cycle de vie d'un projet et d'articuler sa présentation de façon cohérente. Ce découpage est représenté dans la figure ci-dessous.
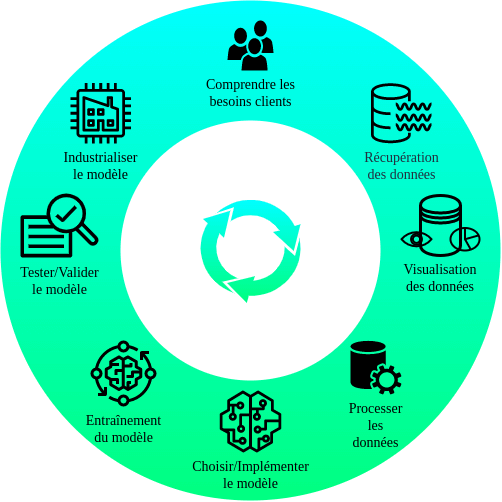
Un exemple typique d'interconnexion entre ces tâches est le suivant: Il est parfaitement possible qu'une fois arrivé à l'étape de test et de validation du modèle, le jeu de données recueilli pour entraîner le modèle n'était pas suffisant pour obtenir des résultats satisfaisants. Il sera donc nécessaire de récupérer de nouvelles données pour entraîner de nouveau le modèle et le tester ensuite.
Comprendre et formaliser les besoins client et métier
Comme pour tout projet (Machine Learning ou non) il est indispensable de savoir quelle est la problématique que l'on souhaite résoudre et quelle solution y apporter. Les projets de Machine de Learning sont des processus longs, du fait qu'ils nécessitent notamment de collecter une grande quantité de données afin d'apporter un réponse robuste, fiable et stable. Quels sont les enjeux, les services à fournir, la solution devra-t-elle être maintenable, facilement interprétable par les parties prenantes sont des exemples de questions qui permettront de façonner sa réalisation.
De plus, les données à manipuler peuvent être sensibles (confidentialité et anonymisation par exemple) et il faut s'assurer que leur utilisation ne franchit pas les limites légales, qui peuvent être différentes d'un pays à un autre.
En reposant sur la méthode scientifique, la bonne réalisation du projet de Machine Learning nécessite de définir des objectifs quantifiables afin d'indiquer quel type de données recueillir (numériques, images, vidéos...), quels résultats attendre (données de sortie) et de définir quelle classe de modèle de Machine Learning (apprentissage supervisé/non supervisé, par renforcement...) sera la plus adaptée.
Pour reprendre l'exemple précédent, c'est précisément en se fixant des objectifs quantifiables dès le début du projet qu'il sera possible d'évaluer si la quantité de données recueillie est suffisante ou non et limiter ainsi les allers-retours entre les différentes étapes.
Récupération des données
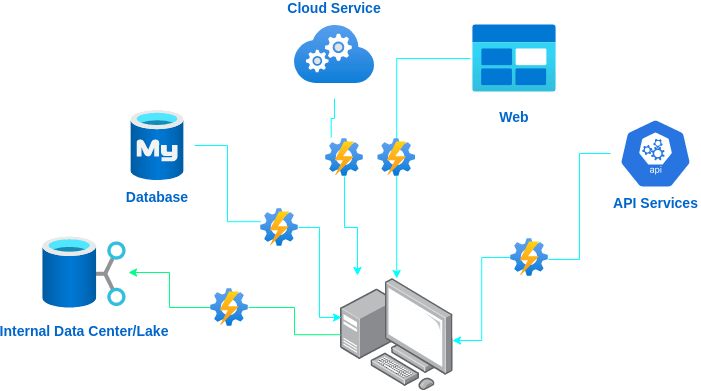
Une fois déterminé le type de données, commence l'étape de leur récupération. En général ces données seront disséminées sur plusieurs sources (bases de données, serveurs Big Data, sites web, API...) qu'il faudra interroger pour rapatrier les données, les organiser et les stocker. Automatiser au plus tôt ces procédures pourra être un gain de temps sur le long terme et la réalisation du projet. En effet, les modèles de Machine Learning étant basés sur l'inférence Bayésienne, tout ajout de nouvelles données nécessitera de le ré-entrainer et de le valider de nouveau. Automatiser la récupération et l'injection de données dans le modèle sera donc un gain de temps précieux pour redéployer le modèle ultérieurement.
Exploration et Visualisation des données
Cette étape ainsi que la suivante sont deux étapes cruciales. Elles permettront une bonne compréhension de l'environnement étudié, d'éviter les biais et de fournir des données de qualité aux algorithmes de Machine Learning choisis (et aussi orienter leur choix). Cette étape permettra de bien visualiser ce que l'on cherche à valoriser, et d'identifier des données manquantes ou incomplètes. Cette étape sera enrichie par les échanges avec le métier concerné qui pourra déjà à ce niveau confirmer ou infirmer des hypothèses. Par exemple, dans le cas de détection d'anomalie, durant cette phase il sera possible de caractériser les signaux "normaux" des signaux "anormaux" et d'en déterminer les variables discriminantes. Pendant cette phase d'analyse de données des algorithmes de Machine Learning et des outils de Data Visualisation pourront être utilisés afin d'effectuer des sélections et constructions de variables discriminantes ("Feature engineering/selection" et "Feature construction").
Préparation des données
Le but de cette étape-ci est de rendre les données exploitables par les algorithmes de Machine Learning en les prétraitant. Comme tout projet informatique, la qualité des données entrantes impactera fortement les données sortantes: "Garbage In, Garbage Out"...
Données manquantes, incohérentes, doublons, potentiellement identifiées durant l'étape précédente devront être nettoyées, normalisées, enrichies ou remplacées par des données artificielles. C'est aussi à ce moment que la confidentialité et la sécurité des données prendra un aspect concret, par exemple en les anonymisant dans le cas de données personnelles. Cette étape est en général la plus chronophage au cours du cycle de vie du projet. D'une part du fait de la volumétrie des données, et d'autre part, du fait du nettoyage et de l'organisation des données, de fréquents allers-retours avec les experts du domaine. Ceci afin de ne pas introduire de biais statistique, par exemple vérifier l'équilibre/représentativité entre chaque type de données du problème afin de ne pas en favoriser un plus qu'un autre.
Les résultats provenant des procédures de "feature engineering" pourront être systématisés à l'ensemble du jeu de données.
Choix et implémentation du/des modèle(s)
Une fois les données prêtes à être injectées dans un algorithme commence la phase à proprement parler de Machine Learning. De nos jours, du fait de la multiplicité de bibliothèques de Machine Learning, cette étape d'implémentation ne représente pas la partie la plus ardue du projet. Il existe des bibliothèques pour une multiplicité de langages comme Python, R, C++, C ou Julia. De ce fait, il est aisé (et recommandé) d'implémenter plusieurs modèles afin de traiter le problème initial.
La complexité du modèle de machine learning à implémenter dépendra de l'objectif métier. S'il est nécessaire de pouvoir interpréter les résultats, un modèle simple avec peu de variables sera à privilégier (par exemple un arbre décisionnel). Au contraire si l'accent sera mis sur la capacité de prédiction de l'algorithme, un modèle très complexe (par exemple basé sur des algorithmes de Deep Learning) permettra une analyse prédictive très fine et précise.
Quel que soit le type de modèle, ils dépendent tous d'un certain nombre de paramètres qui leur sont propres appelés hyperparamètres. Ce sont des variables d'ajustement qui permettront de contrôler le processus d'apprentissage/entrainement du modèle, que nous allons détailler dans la section suivante.
Entrainer le modèle
Cette étape correspond à la partie la plus caractéristique de l'apprentissage automatique. L'entraînement du modèle s'effectue en y injectant les données recueillies et nettoyées dans les étapes précédentes. Dans un modèle d'apprentissage supervisé, elles auront été séparées en variables d'entrée ("feature set") et variables de sortie ("target set"). La phase d'entraînement consiste donc pour le modèle d'améliorer sa capacité, de façon progressive et itérative, à réagir face à une situation donnée, à résoudre un problème complexe ou résoudre une tâche. Le tout en minimisant une fonction d'erreur/de coût. La qualité des données et leur représentativité de la situation à analyser sera cruciale afin de ne pas introduire de biais dans les résultats tout en conservant une précision optimale.
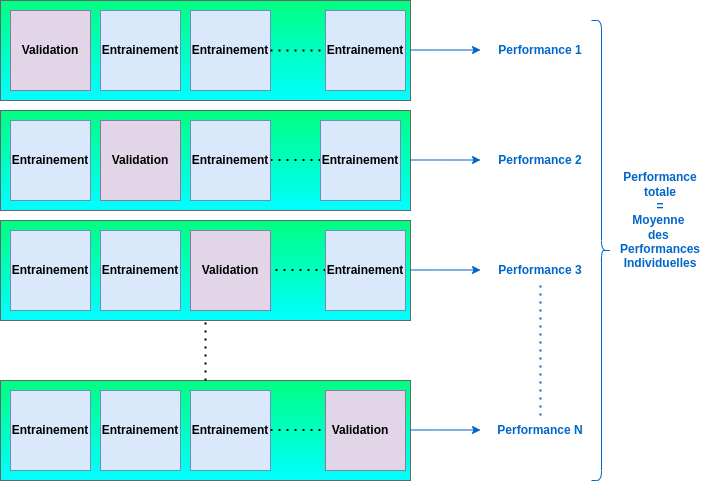
Afin d'éviter d'introduire des biais statistiques, il est d'usage de diviser les jeux de données en 2 ou 3 parties. La première consiste à concevoir/entraîner le modèle ("training set"), la deuxième à le tester ("test set") et la potentielle troisième étape à le valider ("validation set"). Il est préférable d'effectuer cette séparation de façon aléatoire tout en conservant dans chaque partie que la représentativité des données est similaire (par exemple en utilisant la méthode de validation croisée ou "Cross Validation"). Ceci sera particulièrement critique dans le cas où le but sera d'identifier des phénomènes rares, comme la détection d'anomalies.
Cette phase du projet de Machine Learning est très gourmande en ressource de calcul (CPU, GPU) et en temps. Il sera donc nécessaire d'optimiser la quantité de données à injecter (tout en conservant leur représentativité vis-à-vis du jeu initial). Automatiser cette phase le plus rapidement possible sera un gain de temps sur le long terme. Principalement du fait de la cyclicité du processus et afin de pouvoir injecter facilement et rapidement de nouvelles données si le besoin s'en fait sentir.
Evaluer et Valider le modèle
Une fois le modèle implémenté et entraîné sur le "training set" afin de produire des résultats, vient l'étape d'évaluation et de validation du modèle. Si les critères de validation ne sont pas remplis lors d'une première itération, il faudra modifier un certain nombre de paramètres du modèle ou bien ajouter de nouvelles données afin de l'entrainer de nouveau. A chaque nouvelle itération les résultats seront évalués et ce processus itératif continuera jusqu'à obtenir satisfaction, quantifiée de façon objective par un choix de métriques (ou fonctions d'erreur) appropriées.
Pour des modèles de classification, le choix standard est d'utiliser la valeur de la "cross-entropy" et pour des modèles de régression il est communément utilisé des fonctions d'erreur comme la "Mean squared error" (ou MSE) ou bien la "Mean Absolute Error" (ou MAE). Il faut bien comprendre qu'à chaque type de tâche d'apprentissage automatique certaines métriques seront plus appropriées que d'autres. Par exemple, dans le cas d'une détection d'anomalie, en général le choix de la MSE est plus approprié car plus sensible aux valeurs extrêmes car la différence entre la valeur attendue et la valeur prédite par le modèle est élevée au carré.
Il faudra ensuite appliquer le modèle entrainé sur le "training set" sur le "test set" afin de vérifier la capacité de généralisation du modèle entraîné. En effet, le "test set" n'ayant pas été utilisé pour l'entraînement, on teste ici la capacité du modèle à produire des résultats cohérents sur des données qui lui sont inconnues. Cette étape nous permet de construire notre confiance dans le modèle lorsqu'il sera mis en production afin de fournir des résultats fiables sur de nouvelles données. D'où l'importance de choisir des données représentatives de la situation à analyser ou à reproduire.

Les retours critiques du métier seront aussi cruciaux pour la validation du modèle et permettront aussi de choisir quel modèle est le plus performant à travers une restitution claire et pédagogique des résultats.
Une fois la visualisation des données terminée et le modèle validé, la prochaine étape sera, avec l'aide des équipes IT, d'industrialiser la solution et de l'intégrer dans l'infrastructure existante de l'entreprise.
Déploiement du modèle
Une fois le modèle jugé suffisamment robuste et fiable, son déploiement en production va pouvoir commencer. Cette étape n'est plus à proprement parler de la datascience et pourra être effectué par les équipes IT/d'ingénierie logicielle pour industrialiser la solution et l'intégrer dans l'infrastructure existante de l'entreprise.
Concernant l'aspect technique de la mise en production il faudra se reposer la question des technologies utilisée pour déployer l'application (quel langage, quelle technologie, open source ou pas, infrastructure cloud ou pas, privée ou publique…) par rapport à la phase de prototypage.
La première étape sur le chemin de déploiement du modèle sera de préparer et configurer les pipelines de données. Afin d'assurer une mise à l'échelle correcte il faut s'assurer que les pipelines de données sont structurés efficacement et sont capables de fournir des données pertinentes et de haute qualité. Comme dit précédemment avoir anticipé ce genre de problématiques dans les étapes en amont du processus accélèrera ce processus.
Dans un deuxième temps, une fois dans un environnent de production, il faudra continuellement alimenter le modèle en nouvelles données. Ces données devront être les meilleures possibles afin que le modèle continue d'être actualisé pour rester pertinent et leurs sources les plus diverses possible, par rapport aux étapes de prototypage du modèle.
Comme toute application déployée en production des tests rigoureux devront être mis en place et automatisés pour s'assurer que toute nouvelle version réponde bien aux exigences initiales du projet et permettre une croissance contrôlée des pipelines et modèles de données. La conception de protocoles robustes de surveillance de provenance et de qualité des nouvelles données empêcheront une dérive du modèle mettant en danger sa cohérence et sa pertinence. Le but étant d'être en capacité d'intégrer et de livrer continuellement le produit.
Conclusion
Le développement d'un projet de Machine Learning est un processus cyclique, de la phase de prototypage à sa mise en production. Les modèles sont généralement entraînés avec des données, et la capacité prédictive est liée à la qualité des données. Au fur et à mesure que le temps passe l'inclusion de nouvelles données modifie l'environnement à partir duquel le modèle est entrainé et sa précision commence à chuter de façon concluante.
La clé de la réussite du projet est d'automatiser et de rationnaliser le processus au maximum du possible. Automatiser afin de réduire le temps de développement et de s'assurer de la qualité des données (cette partie étant particulièrement chronophage en début de projet). Rationaliser afin de pouvoir prendre de bonnes décision vis-à-vis de la validation et du suivi de l'évolution du modèle au cours du temps, avec l'appui des connaissances du métier.
Retour aux articles