Après notre précédent article sur l’étude de ROI pour le déploiement d’un progiciel , on poursuit sur les sujets d’urbanisation avec cette fois-ci, le déploiement d’un ETL.
Le constat
Le système d’information doit être un outil permettant d’accompagner la croissance et la stratégie de l’entreprise. Cet article décrit un cas d’usage, celui d’une PME / ETI en pleine croissance, qui a initié en 2021 une réflexion sur l’urbanisation de son système d’information. La société utilise alors plusieurs outils répondant à différents besoins :
- Un ERP, permettant aux collaborateurs de saisir leurs imputations projets, leurs demandes d’absences et leurs notes de frais. Cet ERP dispose également d’un module CRM utilisé par les commerciaux, d’un module pour la gestion des candidats. Il est aussi utilisé par le service ressources humaines pour le suivi administratif des collaborateurs (contrats de travail, suivi des visites médicales, des entretiens, des demandes de formation…). Le service finance, de son côté, exploite l’ERP pour gérer les projets clients, la facturation, et les achats.
- Un logiciel de paie, utilisé pour la préparation des bulletins de paie et la production des déclarations sociales (qui servent à payer les cotisations sociales et à transmettre les données des salariés aux organismes sociaux : CPAM, Urssaf, Pôle Emploi, etc)
- Un logiciel de comptabilité, qui est dédié à la production des journaux comptables (les documents qui recensent l’ensemble des opérations financières de l’entreprise).
Ces trois outils ne sont pas interfacés, ce qui occasionne des saisies manuelles multiples, et une charge de travail importante dédiée au contrôle de cohérence des données. L’extraction fréquente et massive de données dans des fichiers Excel présente un risque de perte de confidentialité de la donnée.
L’extraction des données depuis ces outils et la production d’indicateurs de pilotage sont très chronophages.
Le schéma ci-dessous résume la situation.
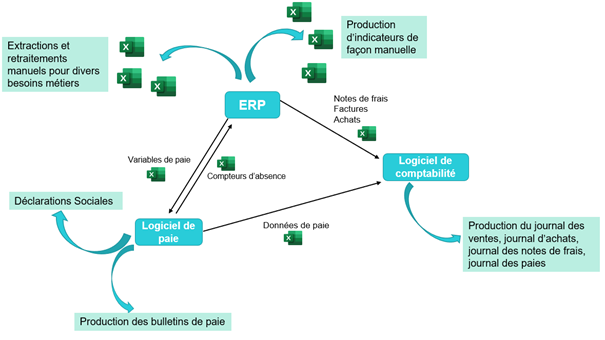
Face à ce constat, le souhait de l’entreprise est de disposer d’un moyen d’interfacer les logiciels entre eux, d’automatiser certains traitements manuels, et de rassembler des données provenant de différentes sources pour en obtenir une vision unifiée.
Côté utilisateurs, l’objectif est double :
- Mettre à disposition une information fiable et pertinente (reporting, indicateurs) auprès des utilisateurs concernés.
- Permettre un gain de temps aux équipes en structure pour se consacrer à leur cœur de métier et non à de la saisie et du contrôle de données.
L’entreprise s’oriente alors vers la mise en place d’un outil d’intégration des données (data integration) / ETL pour répondre à ces problématiques.
Mais qu'est-ce qu'un ETL ?
ETL est l’acronyme de Extract – Transform – Load . Il s’agit d’un outil qui permet d’extraire des données de plusieurs sources (telles que des bases de données, des logs d’activité, des fichiers, des pages web, etc.), de les transformer selon des règles définies, puis de les charger vers d’autres outils ou dans un entrepôt de données (Data warehouse).
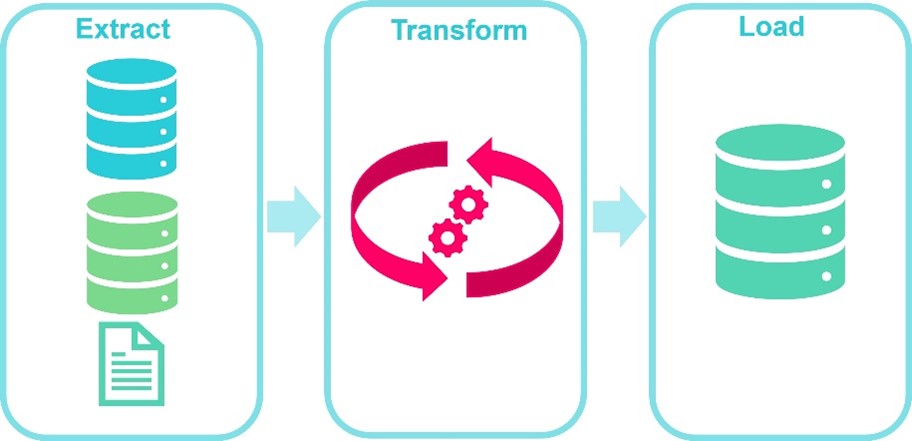
Les étapes du projet de déploiement
- Identifier les flux à automatiser
La première étape est d’identifier les flux de données à automatiser. L’interview des utilisateurs impactés permet de dégager les grandes problématiques et d’identifier lesquelles pourraient être résolues grâce à de l’automatisation. - Prioriser les flux
Dans un second temps, la priorisation des sujets se fait en estimant le gain de temps attendu par une automatisation partielle ou totale, en prenant en compte la criticité des données traitées ainsi que le risque de « non-qualité » (risque juridique, financier ou en termes d’image en cas de d’erreur ou d’incapacité à produire la donnée). - Benchmark et choix d’une solution
Une fois les flux prioritaires identifiés, un benchmark des solutions ETL du marché est lancé par la DSI. Une analyse globale du marché des ETL et des premiers contacts avec les éditeurs permettent d’identifier une short-list de trois solutions. Un cahier des charges fonctionnel et technique est fourni aux éditeurs, qui répondent tous les trois à la consultation. Deux solutions sont présélectionnées pour faire l’objet d’un POC (Proof Of Concept). L’une des deux s’avère très pertinente pour répondre aux besoins et est retenue : il s’agit de SnapLogic. - Déploiement de l’ETL
Une fois la solution sélectionnée, les étapes suivantes sont nécessaires pour déployer cet ETL :
- Architecture de la solution
- Définition du modèle de données initial
- Définition et formalisation des processus et méthodes de travail
- Mise en place des outils et environnements :
- Environnement Sandbox pour l’ERP
- Outil de gestion du backlog (Planner)
- Outil de versioning de code (Gitlab)
- Outil de gestion des changements (iTop)
- Environnement ETL de test
- Environnement ETL de production
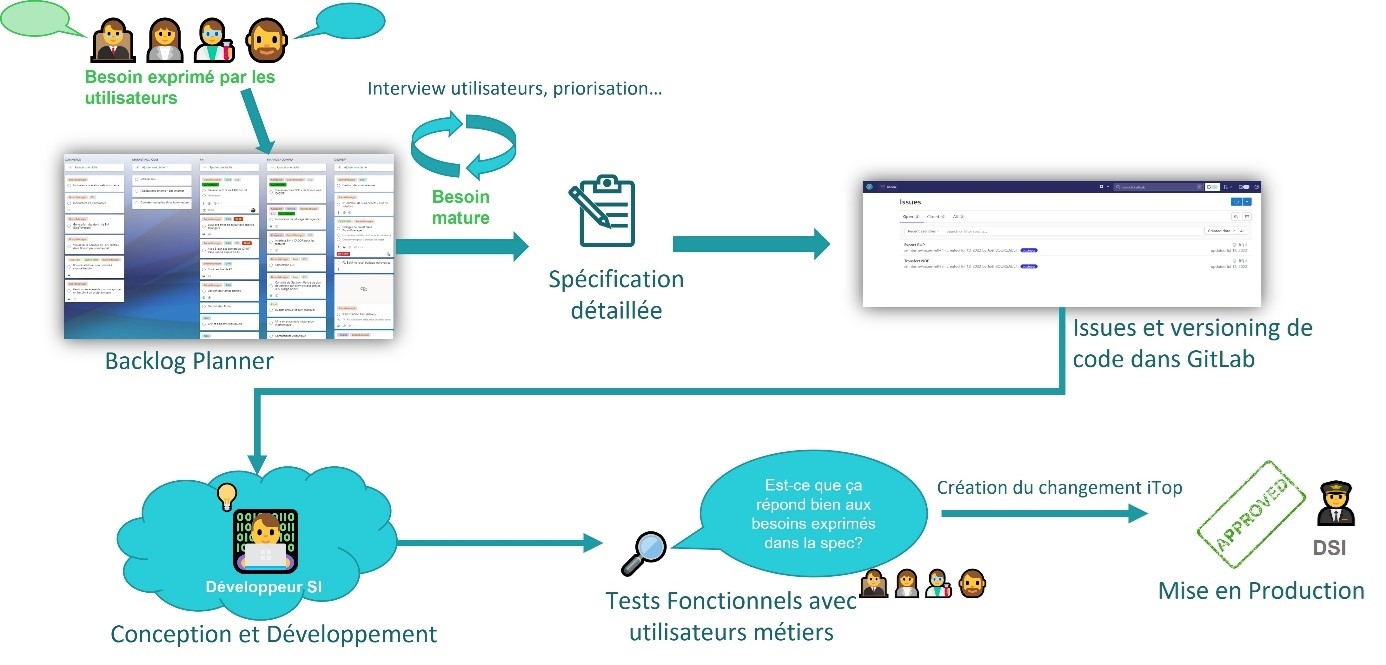
Du besoin métier à la réalisation…
Ça y est, l’ETL est déployé ! L’entreprise est prête à automatiser ses premiers flux de données. L’équipe procède de la façon suivante.
- Etablissement d’un backlog des flux via les remontées utilisateurs (système de cartes dans Planner).
- Priorisation des sujets en fonction de l’urgence des besoins business, du gain de temps attendu et de la criticité des données traitées
- Quand un besoin est jugé « mature », la spécification détaillée est rédigée par l’analyste fonctionnel en collaboration avec le développeur SI et l’expert métier concerné, et une issue typée « business » est créée dans GitLab pour suivre l’avancement du développement et des tests.
- Puis place au développement
- Les tests sont ensuite réalisés en environnement de test
- Et enfin, mise en production du flux après accord du DSI.
Ce processus est résumé dans l’illustration ci-dessous.
Premiers succès
A ce jour, trois flux ont été déployés en production. Ces flux font appel à des fonctionnalités différentes de l’ETL :
- La production du Registre Unique du Personnel, un document que l’employeur doit mettre à disposition de l’inspection du travail et du CSE. Ce flux entièrement automatique nécessite une extraction de données depuis l’ERP, une transformation sur certaines données (agrégation des dates des contrats de travail) et la génération d’un fichier sur un emplacement SharePoint, avec un nettoyage d’historique régulier.
- Le transfert des notes de frais depuis l’ERP vers l’outil de comptabilité : ce flux est lancé à la demande. Il extrait des données de l’ERP, les transforme selon des règles spécifiques, permet à l’utilisateur métier de les catégoriser manuellement, et produit un fichier importable dans l’outil de comptabilité. Ce fichier est ensuite chargé sur un SharePoint.
- La production d’indicateurs de pilotage : ce flux sert à calculer des indicateurs destinés à la direction, concernant l’occupation des effectifs. L’ETL effectue d’abord une extraction de l’ERP, puis procède à une transformation des données suivant plusieurs règles (filtrages, suppressions) afin de générer une base de calcul pertinente, et enfin produit les indicateurs dans un tableau Excel. A terme ces indicateurs pourront être intégrés dans des dashboards Power BI.
Prochaines étapes
L’ETL étant à présent déployé, l’équipe a quitté le mode ‘Projet’ pour passer en mode ‘Run’. Le backlog est mis à jour au fil de l’eau en fonction de l’émergence de nouveaux besoins ou de l’évolution des priorités, ce qui permet de définir une Roadmap des prochains flux.
Les développements réalisés pour les premiers flux ont permis de créer des briques logicielles qui pourront être réutilisées pour les flux suivants, ce qui va fortement améliorer la vitesse de développement et de mise en production.
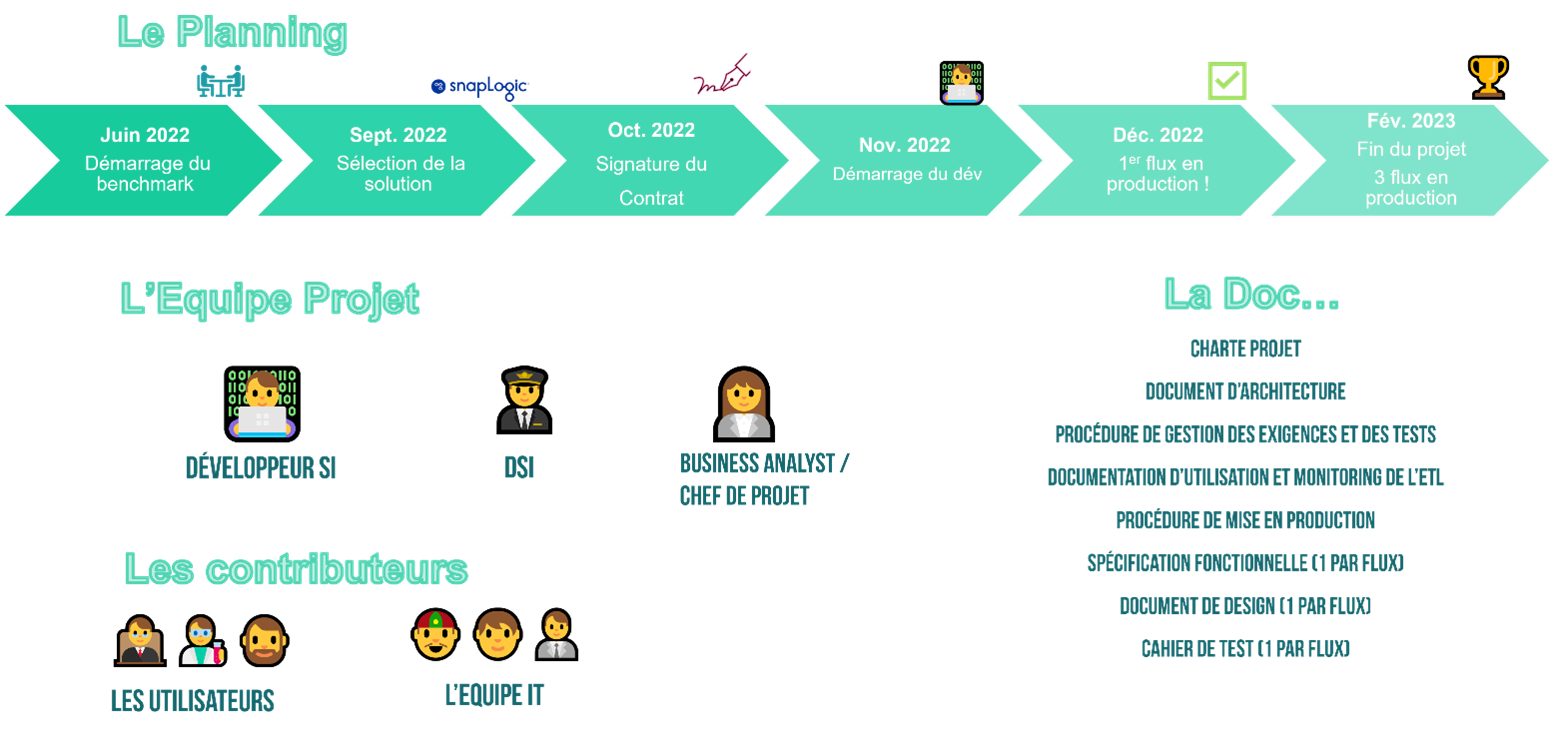
Et pour finir, quelques infos sur le projet :
Retour aux articles