Le sujet de cet article?
Vous l’aurez compris au titre, cet article parle de Data et plus particulièrement de Dataviz. Il expliquera la création du catalogue de visu, fruit du CIR au sein du KZS lab.
Nous en sommes tous conscients, ces dernières années, les évolutions technologiques, la démocratisation d’internet et plus précisément, l’internet des objets, ont créé un flux massif et constant de données. Il est donc devenu vital de pouvoir stocker, traiter, analyser et interpréter ces données : c’est ce qu’on regroupe sous le terme de data sciences.
Dans ce vaste domaine, nous trouvons la data visualisation. Alors la dataviz c’est quoi ?
La dataviz consiste à transformer des données brutes en objets visuels, plus facilement intégrés par notre cerveau, en se basant sur nos perceptions des couleurs, volumes, textures etc. C’est en quelque sorte notre bouée de sauvetage dans cet océan d’informations. Ça permet de « percevoir» les données, en les filtrant ou en faisant émerger du sens, afin de mieux les comprendre et les communiquer.
Alors oui, j’entends déjà venir « la data visualisation ce n’est pas une vraie discipline », «c’est un truc de hippie » ou encore « moi aussi je sais faire des bar charts sous Excel, c’est facile »… Alors oui, maiiiis NON.
Avec ce projet, on essaie de casser un peu les habitudes (mauvaises ou bonnes, à vous de juger) de la dataviz.
Mais pourquoi ce projet ?
Le souci c’est que la dataviz est souvent interprétée comme une discipline secondaire, transversale. On l’utilise dans les autres domaines, à la fin d’un projet, pour faire de jolis rapports, ou comme outil marketing ou publicitaire pour orienter l’opinion de ceux qui la verront. Et du coup, c’est pas souvent très bien utilisé, soyons honnêtes.
Ce projet est parti de ce constat : la plupart des personnes utilisent un panel très réduit de visualisations (à savoir : bar chart OU pie chart OU line chart et c’est tout, à la limite un nuage de points pour les plus scientifiques). Pourtant il existe une grande diversité de visualisations, qui, dans pas mal de situation peuvent se montrer encore plus adaptées au besoin de la personne ! Mais, attention spoiler alerte, pas facile d’utiliser de nouvelles visus quand on ne les connait pas, bah oui…
Et puis, on ne va pas se mentir, dans certains domaines, il y a aussi une réticence au changement : si on demande à Charles, cardiologue depuis 20 ans, d’arrêter avec ses line chart, il va gentiment nous envoyer valser.
Du coup, Ivan, que vous connaissez tous probablement, a mis à disposition ses compétences d’expert dataviz pour monter ce projet. Il a décidé de créer un catalogue de visualisations afin de présenter de nouvelles possibilités de représentations aux utilisateurs, en s’affranchissant des compétences de la personne et du domaine d’application et en partant de la question « Pourquoi visualisez-vous ? Qu’est-ce que vous cherchez à comprendre avec ces données ?». Après pas mal de recherches et tests utilisateurs, le catalogue est né.
Puis ayant d’autres choses à faire, Ivan a pris une stagiaire sur ce projet, afin d’améliorer l’outil (coucou c’est moi).
Bon ça parle beaucoup mais c’est quoi ce catalogue Dataviz alors ?
En gros, le catalogue prend la forme d’une application web. L’utilisateur peut renseigner ses données et ses besoins et ainsi être guidé lors du choix d’un type de visualisation adapté. Il est ensuite accompagné lors du mapping de ses données sur les capacités visuelles de cette visualisation, pour enfin générer une visualisation fonctionnelle.
Ça paraît encore un peu flou ?
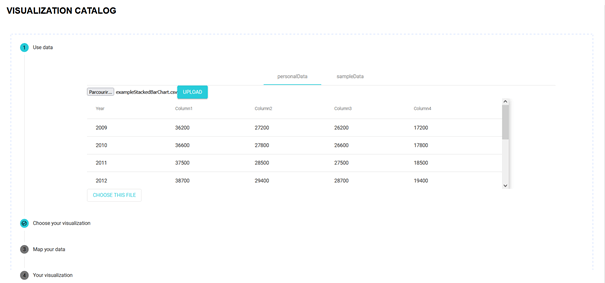
Alors plus en détails : en arrivant sur l’appli, vous voyez 4 points : les 4 étapes à suivre pour obtenir la réponse à vos besoins. Ces points sont organisés sous forme d’un fil d’Ariane.
Dans votre quête vers LA visualisation de vos rêves (du genre qui vous vaudra des applaudissements en fin de présentation) :
- Premier stop : uploader vos données si vous en avez OU choisissez des données exemples, proposées sur l’appli.
- Deuxième stop : l’expression de votre besoin, par sélection/désélection d’icônes.
Comment expliquer à l’appli ce que vous souhaitez ? Alors grâce au travail d’Ivan, c’est super simple !
Vous voyez des icônes vertes appelées « Insights » (en. idée, intuition) qui représentent des notions assez « haut-niveau » de ce que vous souhaitez visualiser dans vos données. Par exemple, est-ce que vous voulez mettre en avant des comparaisons dans vos données ? Ou plutôt des valeurs extrêmes ? Ou les deux (soyons fou).
Vous pouvez sélectionner autant d’icônes que vous le souhaitez en fonction de la complexité de votre besoin. Mais attention ! Plus vous sélectionnez d’insights, moins de visualisations pourront répondre à votre besoin. Des fois, il est plus judicieux de découper son besoin en plusieurs sous-besoins afin de composer des visu sous forme de dashboard (spoiler alerte, ça pourrait être le sujet du prochain stagiaire dataviz).
En dessous des icônes vertes, vous l’aurez compris, les icônes bleues représentent les visualisations présentes dans notre catalogue. La sélection d’insights diminue le panel de visualisations répondant à ce besoin.
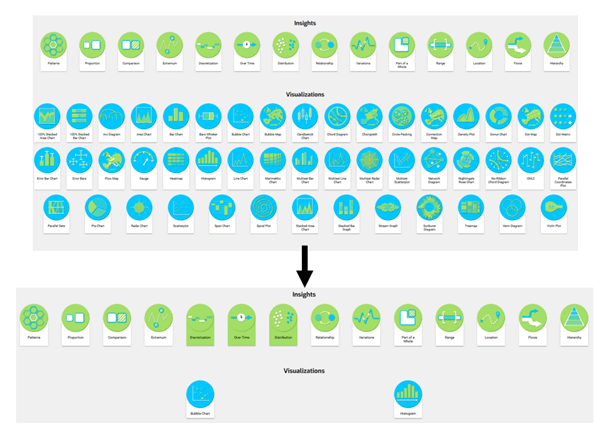
Après ce jeu de click/unclick, vous choisissez enfin une visu : c’est parti pour le 3ème et avant dernier stop !
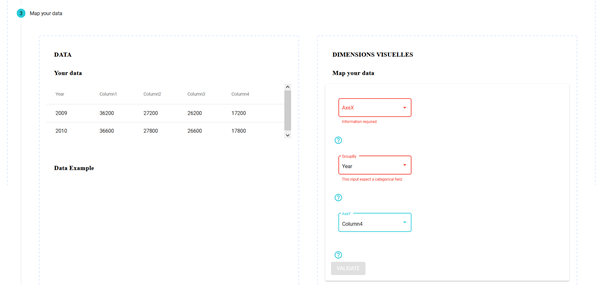
- Troisième stop : Lors de cette étape, on a d’un côté les données que vous avez choisi au tout début. Et d’un autre côté, vous retrouvez les entrées attendues par la visualisation pour se générer. Il vous suffira de mapper vos données dans les différentes entrées attendues et de valider votre choix. Rassurez-vous, cette étape est en partie guidée (des petits messages rouges apparaîtront si vous faites n’importe quoi, n’hésitez d’ailleurs pas à nous faire remonter vos feedbacks pour améliorer le guidage).
- Quatrième et dernier stop : vous pouvez enfin voir le résultat de tous vos efforts. A cette étape : soit vous êtes satisfaits (ce qu’on espère, on ne va pas se mentir), soit vous ne trouvez toujours pas votre bonheur dans cette visualisation et vous pouvez réitérer les étapes précédentes, pour la compléter d’une seconde, ou en trouver une autre qui correspondrait mieux. A cette étape, on peut aussi vous conseiller des visualisations assez « proches » mais différentes quand même.
Et rapidement, côté technique, comment l’appli a été faite ?
Côté frontend, l’appli a été réalisée avec Angular10. C’est un framework côté client, open source et basé sur Typescript. Il permet la création de « single page applications » : applications accessibles via une page web unique.
Côté backend, on utilise une base de données relationnelle : Neo4j. Les bases de données Neo4j ne sont pas organisées de manière traditionnelles comme SQL sous forme de tables. Elles ont une structure plus flexible, en graphe, où les relations sont aussi stockées dans la BDD (simplifiant grandement les requêtes dans notre cas).
Et pour faire le pont entre back et front, il y a GraphQL, qui permet de faire les requêtes sur le back et de modifier le front en conséquence.
Pour terminer : le déploiement ! Alors difficile d’en parler précisément pour moi, newbie en informatique (#Jen dans The IT Crowd si vous avez la ref).

Mais globalement, une fois l’application fonctionnelle, elle a été dockerisée : 3 images : 1 pour le front, 2 pour le back (graphQL et Neo4j).
Ensuite, Kubernetes intervient pour la mise en prod, en faisant office d’orchestrateur de conteneurs. Là il a fallu créer quelques déploiement (permettant de gérer des pods : groupe de 1 ou plusieurs conteneurs) puis des services pour rendre l’appli accessible aux requêtes extérieures.
Quelques config maps et secret, et le déploiement devrait être terminé !
Retour aux articles