Google a présenté très récemment un outil de segmentation vidéo intégré à la fonctionnalité Stories de Youtube dans sa version mobile. Disponible uniquement dans la version beta de l’application, voici comment Google est parvenu à faire fonctionner une telle technique sur un simple Smartphone.
Le but de ce nouvel outil est de transporter l’utilisateur dans des endroits amusants en remplaçant l’arrière-plan des images retournées par la caméra par un environnement totalement ou partiellement virtuel. Cette opération est couramment utilisée dans le milieu du cinéma par exemple, et nécessite un environnement de studio avec un écran vert permettant de retirer l’arrière-plan de l’image à l’aide d’une technique appelée incrustation Chroma.
Grâce à son nouvel outil, Google permet aux utilisateurs de créer un rendu similaire à cette technique sans utiliser d’équipement spécialisé, uniquement à l’aide d’un Smartphone. Mais alors, comment font-ils ?
Réseau de neurones à la rescousse
Pour beaucoup de tâches de vision par ordinateur, les réseaux de neurones et plus spécifiquement les réseaux de neurones convolutifs profonds (ou Deep Learning) se sont imposés comme la technique de référence. Une de ces tâches est la segmentation sémantique. Celle-ci a pour objectif d’étiqueter chaque pixel d’une image avec un ensemble de catégories d’objets que le réseau de neurones aura appris à reconnaître.
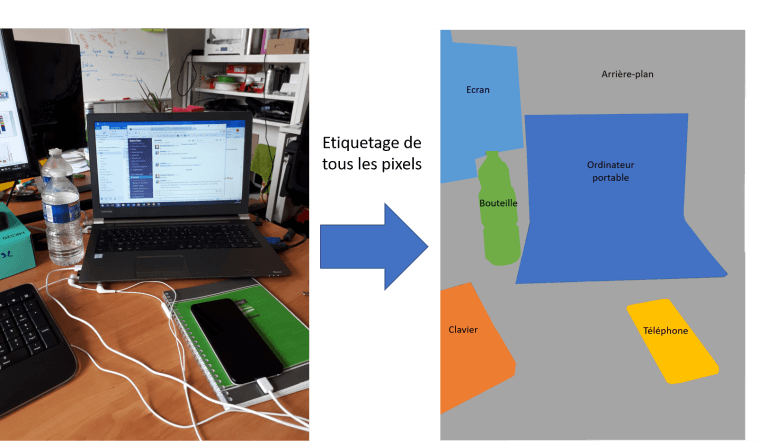 Segmentation Sémantique
Segmentation SémantiqueEn apprenant à un tel algorithme à reconnaître des personnes, il devient alors capable de segmenter une image en deux catégories : une personne ou un arrière-plan. C’est ce type de technique qu’a utilisé Google dans son outil. Habituellement, ces solutions s’exécutent sur des machines embarquant de grosses capacités matérielles (cartes graphiques notamment), il a donc fallu faire quelques adaptations afin de répondre aux exigences de l’application :
- Temps réel : l’algorithme doit être capable de traiter au moins 30 images par seconde sur un Smartphone
- Vidéo : l’algorithme doit tenir compte de la relation temporelle entre les différentes images
- Qualité : l’algorithme doit fournir un résultat précis afin que le rendu soit réaliste
Les optimisations réalisées
Pour parvenir à leurs fins, les ingénieurs de Google sont partis d’un réseau de neurones totalement convolutif couramment utilisé pour des tâches de segmentation sémantique.
Pour obtenir un résultat de qualité, il faut fournir à l’algorithme des données d’apprentissage de qualité. Une grosse partie du travail a donc consisté à annoter plusieurs milliers d’images de manière précise. Pour chacune d’elles, tous les éléments d’avant-plan ont ainsi été localisés, le reste de l’image étant donc catégorisé comme élément d’arrière-plan.

Exemple d'annotation (source)
Grâce au jeu de données créé, il est alors possible à l’algorithme, à partir d’une image fournie en entrée, de générer un masque de celle-ci en regroupant tous les éléments détectés sous une même catégorie (avant-plan), et tous le reste de l’image sous une autre catégorie (arrière-plan).
Afin de profiter de la consistance temporelle entre les images successives, l’idée des ingénieurs de Google a été de fournir en entrée de l’algorithme le masque généré sur l’image précédente, en plus de l’image courante. L’algorithme a alors été entraîné à générer le masque d’une image non plus uniquement en fonction de l’image fournie en entrée, mais également en fonction du masque précédent, ce qui permet à l’application de fournir une continuité temporelle d’une image à l’autre.
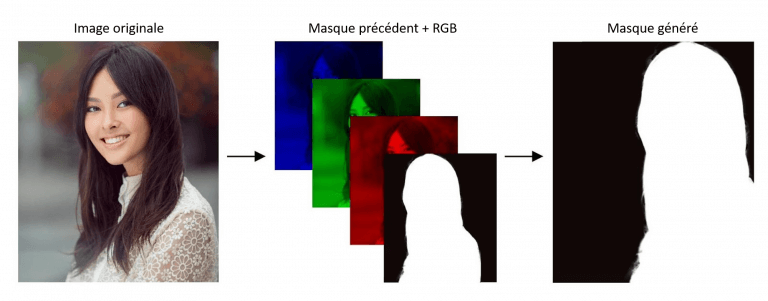 Masque précédant utilisé en entrée de l'algorithme
Masque précédant utilisé en entrée de l'algorithme
Enfin, différentes améliorations ont été apportées à l’architecture du réseau de neurones afin d’optimiser un peu plus ses performances en termes de précision et de vitesse d’exécution :
- Utilisation de noyaux de convolution avec des pas importants sur l’image d’entrée
- Utilisation de connexions « skip » entre la phase d’encodage et de décodage
- Réduction importante du nombre de noyaux dans les goulots d’étranglement
- Ajout de couches de type « DenseNet » à la fin du réseau
Toutes les modifications et améliorations décrites permettent à l’algorithme de Google de s’exécuter en temps réel sur Smartphone, opérant ainsi plus de 100 images par seconde sur un iPhone 7, ou encore 40 images par seconde sur un Pixel 2.
Conclusion
En proposant un tel algorithme sur Smartphone, Google a réalisé un travail remarquable. En effet, aujourd’hui les réseaux de neurones convolutifs sont quasiment exclusivement employés sur des plateformes embarquant de puissantes cartes graphiques. Ce travail est ainsi la preuve que bientôt, de nombreux algorithmes efficaces sur ces plateformes, pourront également l’être sur nos Smartphones.
Les technologies associées au Deep Learning montrent une fois de plus les résultats impressionnants qu’elles peuvent apporter, et notamment pour la Réalité Augmentée, où la compréhension de l’environnement physique est un élément essentiel à la bonne fusion des éléments réels et virtuels.
Retour aux articles